2021年9月5日更新:
深度强化学习研究方向概述
注:本段内容摘自知乎https://zhuanlan.zhihu.com/p/342919579
赶时间请直接看加粗的四种算法,它们占据不同的生态位,请根据实际任务需要去选择他们,在强化学习的子领域(多智能体、分层强化学习、逆向强化学习也会以它们为基础开发新的算法):
- 离散动作空间推荐:Dueling DoubleQN(D3QN)
- 连续动作空间推荐:擅长调参就用TD3,不擅长调参就用PPO或SAC,如果训练环境 Reward function 都是初学者写的,那就用PPO
来自另外一个大佬的建议:对于连续控制任务,推荐SAC、TD3和PPO,三种算法都值得试一试并从中择优;对于离散控制任务,推荐SAC-Discrete(即离散版SAC)和PPO。
1.离散的动作空间 discrete action space
DQN(Deep Q Network)可用于入门深度强化学习,使用一个Q Network来估计Q值,从而替换了 Q-table,完成从离散状态空间到连续状态空间的跨越。Q Network 会对每一个离散动作的Q值进行估计,执行的时候选择Q值最高的动作(greedy 策略)。并使用 epslion-greedy 策略进行探索(探索的时候,有很小的概率随机执行动作),来获得各种动作的训练数据。
DDQN(Double DQN)更加稳定,因为最优化操作会传播高估误差,所以她同时训练两个Q network并选择较小的Q值用于计算TD-error,降低高估误差。详见和DDQN一样采用了两个估值网络的TD3 曾伊言:强化学习算法TD3论文的翻译与解读
Dueling DQN,Dueling DQN 使用了优势函数 advantage function(A3C也用了):它只估计state的Q值,不考虑动作,好的策略能将state 导向一个更有优势的局面。原本DQN对一个state的Q值进行估计时,它需要等到为每个离散动作收集到数据后,才能进行准确估值。然而,在某些state下,采取不同的action并不会对Q值造成多大的影响,因此Dueling DQN 结合了 优势函数估计的Q值 与 原本DQN对不同动作估计的Q值。使得在某些state下,Dueling DQN 能在只收集到一个离散动作的数据后,直接得到准确的估值。当某些环境中,存在大量不受action影响的state,此时Dueling DQN能学得比DQN更快。
D3QN(Dueling Double DQN)。Dueling DQN 与Double DQN 相互兼容,一起用效果很好。简单,泛用,没有使用禁忌。任何一个刚入门的人都能独立地在前两种算法的基础上改出D3QN。在论文中使用了D3QN应该引用DuelingDQN 与 DoubleDQN的文章。
Noisy DQN,探索能力稍强。Noisy DQN 把噪声添加到网络的输出层之前值。原本Q值较大的动作在添加噪声后Q值变大的概率也比较大。这种探索比epslion-greedy随机选一个动作去执行更好,至少这种针对性的探索既保证了探索动作多样,也提高了探索效率。
====估计Q值的期望↑ ↓估计Q值的分布====
- Distributional RL 值分布RL(C51,Distributional Perspective RL)。在DQN中,Q Network 拟合了Q值的期望,期望可以用一个数值去描述,比较简单。在值分布DQN中,Q Network 拟合了Q值的分布,Q值分布的描述就要麻烦一些了,但是训练效果更好。为C51的算法使用了这种方法,C表示Categorical,51表示他们将值分布划分51个grid。最终在雅达利游戏 Atari Game 上取得好结果。
- QR-DQN(分位数回归 Quantile Regression),使用N个分位数去描述Q值分布(这种方法比C51划分51个grid的方法更妙,我推荐看 QR-DQN - Frank Tian)。根据分位数的分布画出核分布曲线,详见 Quantile-respectful density estimation based on the Harrell-Davis quantile estimator
- Rainbow DQN,上面提及的DQN变体很多是相互兼容的,因此 David Sliver 他们整合了这些变体,称为Rainbow。
- Ape-X DQN(Distributed Prioritized Experience Replay),也是 David Sliver 他们做的。使用了Distributed training,用多个进程创建了多个actor去与环境交互,然后使用收集到的数据去训练同一个learner,用来加快训练速度。Prioritized Experience Replay(优先经验回放 PER 下面会讲)。Ape-X通过充分利用CPU资源,合理利用GPU,从而加快了训练速度。注意,这不等同于减少训练总步数。NVIDIA 有一个叫 Apex的库,用于加速计算。
2.连续的动作空间 continuous action space
- DDPG(Deep DPG ),可用于入门连续动作空间的DRL算法。DPG 确定策略梯度算法,直接让策略网络输出action,成功在连续动作空间任务上训练出能用的策略,但是它使用 OU-noise 这种有很多超参数的方法去探索环境,训练慢,且不稳定。
- soft target update(软更新),用来稳定训练的方法,非常好用,公式是
,其中 theta是使用梯度进行更新的网络参数,theta’ 是使用了软更新的目标网络target network参数,tau略小于1。软更新让参数的更新不至于发生剧变,从而稳定了训练。从DDPG开始就广泛使用,并且在深度学习的其他领域也能看到它的身影,如 谷歌自监督 BYOL Bootstrap Your Own Latent ,看论文的公式(1),就用了soft target update
- TD3(TDDD,Twin Delay DDPG),擅长调参的人才建议用,因为它影响训练的敏感超参数很多。它从Double DQN那里继承了Twin Critic,用来降低高估误差;它用来和随机策略梯度很像的方法:计算用于更新TD-error的Q值时,给action加上了噪声,用于让Critic拟合更平滑的Q值估计函数。TD3建议 延迟更新目标网络,即多更新几次网络后,再使用 soft update 将网络更新到target network上,我认为这没有多大用,后来的其他算法也不用这个技巧。TD3还建议在计算Q值时,为动作添加一个噪声,用于平滑Critic函数,在确定策略中,TD3这么用很像“随机策略”。详见 曾伊言:强化学习算法TD3论文的翻译与解读
- D4PG(Distributed Distributional DDPG),这篇文章做了实验,证明了一些大家都知道好用的trick是好用的。Distributed:它像 Ape-X一样用了 多线程开了actors 加快训练速度,Distributional:Q值分布RL(看前面的C51、QR-DQN)。DDPG探索能力差的特点,它也完好无缺地继承了。
在C51算法论文标题中,Distributional Perspective 指 Q值分布的表示。在Ape-X DQN 标题中, Distributed training 指分布式训练。我曾混淆过它们。
====确定策略梯度↑ ↓ 随机策略梯度====
- Stochastic Policy Gradient 随机策略梯度,随机策略的探索能力更好。随机策略网络会输出action的分布(通常输出高斯分布 均值 与 方差,少数任务下用其他分布),探索的噪声大小由智能体自己决定,更加灵活。但是这对算法提出了更高的要求。
- A3C(Asynchronous Advantage Actor-Critic),Asynchronous 指开启多个actor 在环境中探索,并异步更新。原本DDPG的Critic 是 Q(s, a),根据state-action pair 估计Q值,优势函数只使用 state 去估计Q值,这是很好的创新:降低了随机策略梯度算法估计Q值的难度。然而优势函数有明显缺陷:不是任何时刻 action 都会影响 state的转移(详见 Dueling DQN),因此这个算法只适合入门学习「优势函数 advantage function」。如果你看到新论文还在使用A3C,那么你要怀疑其作者RL的水平。此外,A3C算法有离散动作版本,也有连续动作版本。A2C 指的是没有Asynchronous 的版本。
- TRPO(Trust Region Policy Optimization),信任域 Trust Region。连续动作空间无法每一个动作都搜索一遍,因此大部分情况下只能靠猜。如果要猜,就只能在信任域内部去猜。TRPO将每一次对策略的更新都限制了信任域内,从而极大地增强了训练的稳定性。可惜信任域的计算量太大了,因此其作者推出了PPO,如果你PPO论文看不懂,那么建议你先看TRPO。如果你看到新论文还在使用TRPO,那么你要怀疑其作者RL的水平。
- PPO(Proximal PO 近端策略搜索),训练稳定,调参简单,robust(稳健、耐操)。PPO对TRPO的信任域计算过程进行简化,论文中用的词是 surrogate objective。PPO动作的噪声方差是一个可训练的矢量(与动作矢量相同形状),而不由网络输出,这样做增强了PPO的稳健性 robustness。
- PPO+GAE(Generalized Advantage Estimation),训练最稳定,调参最简单,适合高维状态 High-dimensional state,但是环境不能有太多随机因数。GAE会根据经验轨迹 trajectory 生成优势函数估计值,然后让Critic去拟合这个值。在这样的调整下,在随机因素小的环境中,不需要太多 trajectory 即可描述当前的策略。尽管GAE可以用于多种RL算法,但是她与PPO这种On-policy 的相性最好。
- PPG(Proximal Policy Gradient),A3C、PPO 都是同策略 On-policy,它要求:在环境中探索并产生训练数据的策略 与 被更新的策略网络 一定得是同一个策略。她们需要删掉已旧策略的数据,然后使用新策略在环境中重新收集。为了让PPO也能用 off-policy 的数据来训练,PPG诞生了,思路挺简单的,原本的On-policy PPO部分该干啥干啥,额外引入一个使用off-policy数据进行训练的Critic,让它与PPO的Critic共享参数,也就是Auxiliary Task,参见 Flood Sung:深度解读:Policy Gradient,PPO及PPG ,以及白辰甲:强化学习中自适应的辅助任务加权(Adaptive Auxiliary Task Weighting)。这种算法并不是在任何情况下都能比PPO好,因为PPG涉及到Auxiliary task,这要求她尽可能收集更多的训练数据,并在大batch size 下面才能表现得更好。
- Interpolated Policy Gradient NIPS.2017,反面例子,它试图基于 On-policy TRPO 改出一个 能利用 off-policy 数据的TRPO来(就像PPO→PPG),然而Interpolated Policy Gradient 强行地、错误地使用off-policy 数据对Critic 进行训练。结果在其论文中放出的结果中,它的性能甚至比A3C还差,只是比TRPO、DDPG略好(但是它故意没有和比它好的算法在同一个任务下比较:论文结果很诚实,但是用事实说谎)。
- Soft Q-learning(Deep Energy Based Policy)是SAC的前身,最大熵算法的萌芽,她的作者后来写出了SAC(都叫soft ***),你可以跳过Soft QL,直接看SAC的论文。黄伟:Soft Q-Learning论文阅读笔记
- SAC(Soft Actor-Critic with maximum entropy 最大熵),训练很快,探索能力好,但是很依赖Reward Function,不像PPO那样随便整一个Reward function 也能训练。PPO算法会计算新旧策略的差异(计算两个分布之间的距离),并让这个差异保持在信任域内,且不至于太小。SAC算法不是on-policy算法,不容易计算新旧策略的差异,所以它在优化时最大化策略的熵(动作的方差越大,策略的熵越高)。
- SAC(Automating Entropy Adjustment/ Automating Temperature Parameter
自动调整温度系数并维持策略的熵在某个值附近)一般我们使用的SAC是这个版本的SAC,它能自动调整一个叫温度系数alpha 的超参数(温度越高,熵越大)。SAC的策略网络的优化目标=累计收益+ alpha*策略的熵。一般在训练后期,策略找到合适的action分布均值时,它的action分布方差越小,其收益越高,因而对“累计收益”进行优化,会让策略熵倾向于减小。SAC会自动选择合适的温度系数,让策略的熵保持一种适合训练的动态平衡。SAC会事先确定一个目标熵 target entropy(论文作者的推荐值是 log(action_dim)),如果策略熵大于此值,则将alpha调小,反之亦然。从这个角度看,SAC就不是最大化策略熵了,而是将策略熵限制在某个合适大小内,这点又与PPO的“保持在信任域内,且不至于太小”不谋而合
3.混合的动作空间 hybrid action space
在实际任务中,混合动作的需求经常出现:如王者荣耀游戏既需要离散动作(选择技能),又需要连续动作(移动角色)。只要入门了强化学习,就很容易独立地想出以下这些方法,所以我没有把它们放在前面:
- 强行使用DQN类算法,把连续动作分成多个离散动作:不建议这么做,这破坏了连续动作的优势。一个良性的神经网络会是一个平滑的函数(k-Lipschitz 连续),相近的输入会有相似的输出。在连续的动作空间开区间[-1, +1]中,智能体会在学了-1,+1两个样本后,猜测0的样本可能介于 -1,+1 之间。而强行将拆分为离散动作 -1,0,+1之后(无论拆分多么精细),它都猜不出 0的样本,一定要收集到 0的样本才能学习。此外,精细的拆分会增加离散动作个数,尽管更加逼近连续动作,但会增加训练成本。
- SAC for Discrete Action Space,把输出的连续动作当成是离散动作的执行概率:SAC for Discrete Action Space 这个算法提供了将连续动作算法SAC应用在离散动作的一条技术路线:把这个输出的动作矢量当成每个动作的执行概率。一般可以直接把离散动作部分全部改成连续动作,然后套用连续动作算法,这方法简单,但是不一定最好的。
- P-DQN (Parameterized DQN),把DQN和DDPG合起来:Q network 会输出每个动作对应的Q值,执行的时候选择Q值高的动作。DDPG与其他策略梯度算法,让Critic预测 state-action的Q值,然后用Critic 提供的梯度去优化Actor,让Actor输出Q值高的动作。现在,对于一个混合动作来说,我们可以让Critic学习Q Network,让Critic也为每个离散动作输出对应的Q值,然后用Critic中 arg max Qi 提供梯度优化Actor。这是很容易独立想出来的方法,相比前两个方案缺陷更小。
- H-PPO (Hybrid PPO),同时让策略网络输出混合动作。连续动作(策略梯度)算法中:DDPG、TD3、SAC使用 状态-动作值函数 Q(state, action),A3C、PPO使用 状态值函数 Q(state)。离散动作无法像连续动作一样将一个action输入到 Q(state, action) 里,因此 Hybird PPO选择了PPO。于是它的策略网络会像Q Network 一样为离散动作输出不同的Q值,也像PPO 一样输出连续动作。(警告,2021-03 前它依然没有开源代码,但论文描述的方法无误)。还有 H-MPO(Hybrid MPO),MPO是PPO算法的改进版。
详见Hybird-PPO 2019-03 这篇文章的 Related Work。知乎上也有 黑猫紧张:PN-46: H-PPO for Hybrid Action Space (IJCAI 2019)
4.改进经验回放,以适应稀疏奖励 sparse reward
训练LunarLander安全降落,它的奖励reward 在降落后+200,坠毁-100。当它还在空中时做任何动作都不会得到绝对值这么大的奖励。这样的奖励是稀疏的。一些算法((其实它的奖励函数会根据飞行器在空中的稳定程度、燃料消耗给出一个很小的reward,在这种)
- Prioritized sweeping 优先清理:根据紧要程度调整样本的更新顺序,优先使用某些样本进行更新,用于加速训练,PER就是沿着这种思想发展出来的
- PER(优先经验回放 Prioritized Experience Replay)使用不同顺序的样本进行对网络进行训练,并将不同顺序对应的Q值差异保存下来,以此为依据调整样本更新顺序,用于加速训练。
- HER(后见经验回放 Hindsight Experience Replay)构建可以把失败经验也利用起来的经验池,提高稀疏奖励下对各种失败探索经验的利用效率。
这种操作需要消耗CPU算力去完成。在奖励不稀疏的环境下,用了不会明显提升。在一些环境中,上面这类算法必不可少。例如 Gym 基于收费MuJoCo 的机械臂环境 Robotics Fetch*** ,以及 基于开源PyBullet的机械臂 KukaBulletEnv-v0 。如果不用这类算法,那么我们需要花费更多精力去设计Reward function。
5.在RL中使用RNN
有时候,我们需要观察连续的几个状态才能获得完整的状态。例如赛车游戏,打砖块游戏,我们在只观测单独一帧图片时(部分可观测 Partially Observable state),无法知晓物体的运动速度。因此将相邻几个可观测的状态堆叠起来(stack)可以很好地应对这些难题。
然而,堆叠相邻状态无法应对所有的 PO-MDPs。于是大家想到了用RNN(RNN的入门例子:根据前9年的数据预测后3年的客流)。然而RNN需要使用一整段序列去训练,很不适合TD-errors(贝尔曼公式)的更新方式。如图:普通Actor网络的输入只有state,而使用RNN的Actor网络的输入其实是 Partially Observable state 以及 hidden state。这意味着输入critic网络进行Q值评估的state不完整(不包含RNN内部的hidden state)。为了解决环境的PO-MDPs难题,我们直接引入RNN结构。然而引入RNN结构的行为又给RL带来了RNN内部的PO-MDPs难题。
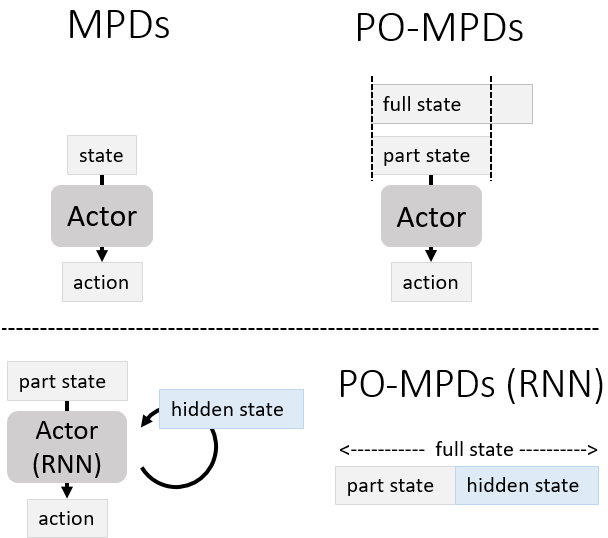
尽管在on-policy算法中,如果使用完整的轨迹(trajectory)进行更新,那么可以缓解critic观测不到 hidden state给训练到来的影响。(如腾讯绝悟的PPO算法使用了RNN),但是这个问题还是没有很好地得到解决。如果想要了解更多使用了RNN的RL算法,请看 羽根:【强化学习TOOLBOX 3】RNN, DRQN, R2D2 。2021年前,我极少复现过效果好的RL+RNN算法,因此我不推荐任何使用了RL+RNN的算法。
虽说 RL+RNN 有各种问题,但是 R2D2 NGU.2020 Agent57.2020 这些算法都用了RNN。我并非认为RNN+RL 不可行,而是认为 在RL中训练RNN 有太多 trick,复现困难。其中,Agent57 训练RNN 的方法很值得借鉴,在论文E. implementation details 写得比较具体。如: 在env transition,也保存了recurrent state)。我有空会继续补充以下三种算法,写于2021-6-18:
R2D2(Recurrent Replay Distributed DQN. ICLR.2019)
NGU(Never Give Up: Learning Directed Exploration Strategies. ICLR. 2020)
Agent57(Agent57: Outperforming the Atari Human Benchmark. 2020)
一种在RL里使用RNN的方法(Note RL+RNN):让使用了RNN 的Actor 输出hidden state 作为action,就像人类记笔记一样。把 part state + hidden state 视为完整的state,把 hidden state + action 视为完整的 action。无论是 state-value function 还是 state-action value function 都能使用这个方法。
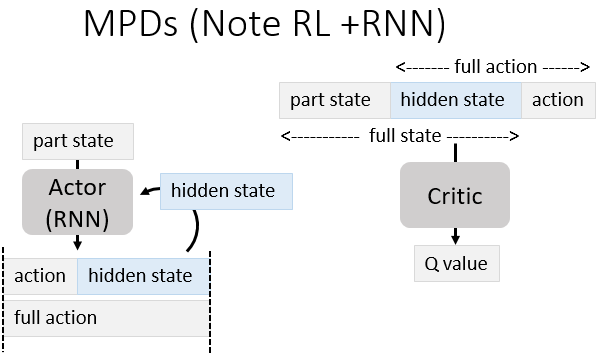
6.强化学习探索
收集不同的state、在同一个state下尝试不同的action 的探索过程非常重要。通过探索收集到足够多的数据,是我们用RL训练出接近最优策略的前提。下面这篇系统介绍了各种探索策略:
Exploration Strategies in Deep Reinforcement Learning - LiLianWeng (我也推荐看她的其他文章)
最近的 First return, then explore Nature.2021 是Go-explore. 2018的升级版
7.多智能体算法 MultiAgent RL
多智能体算法的综述:An Overview of Multi-agent Reinforcement Learning from Game Theoretical Perspective - 2020-12。在比对了多份MARL综述后,只推荐这一篇,它的目录与注释如下:
Contents
1 Introduction
...
1.3 2019: A Booming Year for MARL # 写在2019年前的MARL综述可看性低
2 Single-Agent Reinforcement Learning
...
3 Multi-Agent Reinforcement Learning
...
3.2.5 Partially Observable Settings # state部分可观测的MDPs
3.3 Problem Formulation: Extensive-Form Game
3.3.1 Normal-Form Representation # 普通形式
3.3.2 Sequence-Form Representation # 序列形式
3.4 Solving Extensive-form Games
3.4.1 Solutions to Perfect-Information Games # 完全信息博弈
3.4.2 Solutions to Imperfect-Information Games # 非完全信息博弈(有战场迷雾)
4 The Grand Challenges 38
4.1 The Combinatorial Complexity # 动作空间变大,搜索策略变难
4.2 The Multi-Dimensional Learning Objectives # 状态空间变大,搜索策略变难
4.3 The Non-Stationarity Issue # MARL中,每个智能体的策略总发生改变,导致外部环境不稳定
4.4 The Scalability Issue when N >> 2 # 智能体数量增大,甚至数量改变
5 A Survey of MARL Surveys # 推荐有单智能体基础的人得先看 MARL算法的分类
...
6 Learning in Identical-Interest Games # 合作的MARL
6.1 Stochastic Team Games
6.1.1 Solutions via Q-function Factorisation # 基于Q值
6.1.2 Solutions via Multi-Agent Soft Learning # 基于随机策略
6.2 Dec-POMDP # decentralized PO-MDPs 每个智能体智能看到局部的state 导致的部分可观测
6.3 Networked Multi-Agent MDP 智能体是异构的heterogeneous,而非同源homogeneous
6.4 Stochastic Potential Games
7 Learning in Zero-Sum Games # 竞争的MARL (包含了团体间竞争,团体内合作的情况)
...
7.3.1 Variations of Fictitious Play # 虚拟博弈, 类似于 Model-based 做 Planning
7.3.2 Counterfactual Regret Minimisation # 反事实推理(向左错了,于是考虑向右是否更好)
7.4 Policy Space Response Oracle # 策略空间太大时,考虑用元博弈(meta-game)
7.5 Online Markov Decision Process
7.6 Turn-Based Stochastic Games # 智能体之间轮流做决策,而不是同时做
8 Learning in General-Sum Games
... # 混合了团队博弈合作team games 与 零和博弈竞争zero-sum games 的 General-Sum game
9 Learning in Games with N → +∞ # 无终止状态的博弈(需要考虑信任与背叛)
9.1 Non-Cooperative Setting: Mean-Field Games # 博弈平均场,把其他智能体也视为外部环境
...
END部分多智能体算法的代码以及少量介绍:starry-sky6688/StarCraft 在星际争霸环境 复现了多种多智能体强化学习算法
若智能体间通信没有受到限制(不限量,无延迟),那么我们完全可以把多智能体当成单智能体来处理。适用于部分可观测的MDPs的算法(Partially observable MDPs),在多智能体任务中,每个视角有限的智能体观察到的只是 partially observable state。很多多智能体算法会参与 PO-MDPs 的讨论,由于每个智能体只能观察到局部信息而导致的部分可观测被称为 Dec-POMDP,在上面的MARL综述也有讨论。
7.1 Tutorial and Books
- Deep Multi-Agent Reinforcement Learning by Jakob N Foerster, 2018. PhD Thesis.
- Multi-Agent Machine Learning: A Reinforcement Approach by H. M. Schwartz, 2014.
- Multiagent Reinforcement Learning by Daan Bloembergen, Daniel Hennes, Michael Kaisers, Peter Vrancx. ECML, 2013.
- Multiagent systems: Algorithmic, game-theoretic, and logical foundations by Shoham Y, Leyton-Brown K. Cambridge University Press, 2008.
7.2 Review Papers
- A Survey on Transfer Learning for Multiagent Reinforcement Learning Systems by Silva, Felipe Leno da; Costa, Anna Helena Reali. JAIR, 2019.
- Autonomously Reusing Knowledge in Multiagent Reinforcement Learning by Silva, Felipe Leno da; Taylor, Matthew E.; Costa, Anna Helena Reali. IJCAI, 2018.
- Deep Reinforcement Learning Variants of Multi-Agent Learning Algorithms by Castaneda A O. 2016.
- Evolutionary Dynamics of Multi-Agent Learning: A Survey by Bloembergen, Daan, et al. JAIR, 2015.
- Game theory and multi-agent reinforcement learning by Nowé A, Vrancx P, De Hauwere Y M. Reinforcement Learning. Springer Berlin Heidelberg, 2012.
- Multi-agent reinforcement learning: An overview by Buşoniu L, Babuška R, De Schutter B. Innovations in multi-agent systems and applications-1. Springer Berlin Heidelberg, 2010
- A comprehensive survey of multi-agent reinforcement learning by Busoniu L, Babuska R, De Schutter B. IEEE Transactions on Systems Man and Cybernetics Part C Applications and Reviews, 2008
- [If multi-agent learning is the answer, what is the question?](http://robotics.stanford.edu/~shoham/www papers/LearningInMAS.pdf) by Shoham Y, Powers R, Grenager T. Artificial Intelligence, 2007.
- From single-agent to multi-agent reinforcement learning: Foundational concepts and methods by Neto G. Learning theory course, 2005.
- Evolutionary game theory and multi-agent reinforcement learning by Tuyls K, Nowé A. The Knowledge Engineering Review, 2005.
- An Overview of Cooperative and Competitive Multiagent Learning by Pieter Jan ’t HoenKarl TuylsLiviu PanaitSean LukeJ. A. La Poutré. AAMAS’s workshop LAMAS, 2005.
- Cooperative multi-agent learning: the state of the art by Liviu Panait and Sean Luke, 2005.
7.3 Framework papers
- Mean Field Multi-Agent Reinforcement Learning by Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. ICML 2018.
- Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments by Lowe R, Wu Y, Tamar A, et al. arXiv, 2017.
- Deep Decentralized Multi-task Multi-Agent RL under Partial Observability by Omidshafiei S, Pazis J, Amato C, et al. arXiv, 2017.
- Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games by Peng P, Yuan Q, Wen Y, et al. arXiv, 2017.
- Robust Adversarial Reinforcement Learning by Lerrel Pinto, James Davidson, Rahul Sukthankar, Abhinav Gupta. arXiv, 2017.
- Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning by Foerster J, Nardelli N, Farquhar G, et al. arXiv, 2017.
- Multiagent reinforcement learning with sparse interactions by negotiation and knowledge transfer by Zhou L, Yang P, Chen C, et al. IEEE transactions on cybernetics, 2016.
- Decentralised multi-agent reinforcement learning for dynamic and uncertain environments by Marinescu A, Dusparic I, Taylor A, et al. arXiv, 2014.
- CLEANing the reward: counterfactual actions to remove exploratory action noise in multiagent learning by HolmesParker C, Taylor M E, Agogino A, et al. AAMAS, 2014.
- Bayesian reinforcement learning for multiagent systems with state uncertainty by Amato C, Oliehoek F A. MSDM Workshop, 2013.
- Multiagent learning: Basics, challenges, and prospects by Tuyls, Karl, and Gerhard Weiss. AI Magazine, 2012.
- Classes of multiagent q-learning dynamics with epsilon-greedy exploration by Wunder M, Littman M L, Babes M. ICML, 2010.
- Conditional random fields for multi-agent reinforcement learning by Zhang X, Aberdeen D, Vishwanathan S V N. ICML, 2007.
- Multi-agent reinforcement learning using strategies and voting by Partalas, Ioannis, Ioannis Feneris, and Ioannis Vlahavas. ICTAI, 2007.
- A reinforcement learning scheme for a partially-observable multi-agent game by Ishii S, Fujita H, Mitsutake M, et al. Machine Learning, 2005.
- Asymmetric multiagent reinforcement learning by Könönen V. Web Intelligence and Agent Systems, 2004.
- Adaptive policy gradient in multiagent learning by Banerjee B, Peng J. AAMAS, 2003.
- Reinforcement learning to play an optimal Nash equilibrium in team Markov games by Wang X, Sandholm T. NIPS, 2002.
- Multiagent learning using a variable learning rate by Michael Bowling and Manuela Veloso, 2002.
- Value-function reinforcement learning in Markov game by Littman M L. Cognitive Systems Research, 2001.
- Hierarchical multi-agent reinforcement learning by Makar, Rajbala, Sridhar Mahadevan, and Mohammad Ghavamzadeh. The fifth international conference on Autonomous agents, 2001.
- An analysis of stochastic game theory for multiagent reinforcement learning by Michael Bowling and Manuela Veloso, 2000.
7.4 Joint action learning
- AWESOME: A general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents by Conitzer V, Sandholm T. Machine Learning, 2007.
- Extending Q-Learning to General Adaptive Multi-Agent Systems by Tesauro, Gerald. NIPS, 2003.
- Multiagent reinforcement learning: theoretical framework and an algorithm. by Hu, Junling, and Michael P. Wellman. ICML, 1998.
- The dynamics of reinforcement learning in cooperative multiagent systems by Claus C, Boutilier C. AAAI, 1998.
- Markov games as a framework for multi-agent reinforcement learning by Littman, Michael L. ICML, 1994.
7.5 Cooperation and competition
- Emergent complexity through multi-agent competition by Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, Igor Mordatch, 2018.
- Learning with opponent learning awareness by Jakob Foerster, Richard Y. Chen2, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, Igor Mordatch, 2018.
- Multi-agent Reinforcement Learning in Sequential Social Dilemmas by Leibo J Z, Zambaldi V, Lanctot M, et al. arXiv, 2017. [Post]
- Reinforcement Learning in Partially Observable Multiagent Settings: Monte Carlo Exploring Policies with PAC Bounds by Roi Ceren, Prashant Doshi, and Bikramjit Banerjee, pp. 530-538, AAMAS 2016.
- Opponent Modeling in Deep Reinforcement Learning by He H, Boyd-Graber J, Kwok K, et al. ICML, 2016.
- Multiagent cooperation and competition with deep reinforcement learning by Tampuu A, Matiisen T, Kodelja D, et al. arXiv, 2015.
- Emotional multiagent reinforcement learning in social dilemmas by Yu C, Zhang M, Ren F. International Conference on Principles and Practice of Multi-Agent Systems, 2013.
- Multi-agent reinforcement learning in common interest and fixed sum stochastic games: An experimental study by Bab, Avraham, and Ronen I. Brafman. Journal of Machine Learning Research, 2008.
- Combining policy search with planning in multi-agent cooperation by Ma J, Cameron S. Robot Soccer World Cup, 2008.
- Collaborative multiagent reinforcement learning by payoff propagation by Kok J R, Vlassis N. JMLR, 2006.
- Learning to cooperate in multi-agent social dilemmas by de Cote E M, Lazaric A, Restelli M. AAMAS, 2006.
- Learning to compete, compromise, and cooperate in repeated general-sum games by Crandall J W, Goodrich M A. ICML, 2005.
- Sparse cooperative Q-learning by Kok J R, Vlassis N. ICML, 2004.
7.6 Coordination
- Coordinated Multi-Agent Imitation Learning by Le H M, Yue Y, Carr P. arXiv, 2017.
- Reinforcement social learning of coordination in networked cooperative multiagent systems by Hao J, Huang D, Cai Y, et al. AAAI Workshop, 2014.
- Coordinating multi-agent reinforcement learning with limited communication by Zhang, Chongjie, and Victor Lesser. AAMAS, 2013.
- Coordination guided reinforcement learning by Lau Q P, Lee M L, Hsu W. AAMAS, 2012.
- Coordination in multiagent reinforcement learning: a Bayesian approach by Chalkiadakis G, Boutilier C. AAMAS, 2003.
- Coordinated reinforcement learning by Guestrin C, Lagoudakis M, Parr R. ICML, 2002.
- Reinforcement learning of coordination in cooperative multi-agent systems by Kapetanakis S, Kudenko D. AAAI/IAAI, 2002.
7.7 Security
- Markov Security Games: Learning in Spatial Security Problems by Klima R, Tuyls K, Oliehoek F. The Learning, Inference and Control of Multi-Agent Systems at NIPS, 2016.
- Cooperative Capture by Multi-Agent using Reinforcement Learning, Application for Security Patrol Systems by Yasuyuki S, Hirofumi O, Tadashi M, et al. Control Conference (ASCC), 2015
- Improving learning and adaptation in security games by exploiting information asymmetry by He X, Dai H, Ning P. INFOCOM, 2015.
7.8 Self-Play
- A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning by Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Perolat, David Silver, Thore Graepel. NIPS 2017.
- Deep reinforcement learning from self-play in imperfect-information games by Heinrich, Johannes, and David Silver. arXiv, 2016.
- Fictitious Self-Play in Extensive-Form Games by Heinrich, Johannes, Marc Lanctot, and David Silver. ICML, 2015.
7.9 Learning To Communicate
- Emergent Communication through Negotiation by Kris Cao, Angeliki Lazaridou, Marc Lanctot, Joel Z Leibo, Karl Tuyls, Stephen Clark, 2018.
- Emergence of Linguistic Communication From Referential Games with Symbolic and Pixel Input by Angeliki Lazaridou, Karl Moritz Hermann, Karl Tuyls, Stephen Clark
- EMERGENCE OF LANGUAGE WITH MULTI-AGENT GAMES: LEARNING TO COMMUNICATE WITH SEQUENCES OF SYMBOLS by Serhii Havrylov, Ivan Titov. ICLR Workshop, 2017.
- Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning by Abhishek Das, Satwik Kottur, et al. arXiv, 2017.
- Emergence of Grounded Compositional Language in Multi-Agent Populations by Igor Mordatch, Pieter Abbeel. arXiv, 2017. [Post]
- Cooperation and communication in multiagent deep reinforcement learning by Hausknecht M J. 2017.
- Multi-agent cooperation and the emergence of (natural) language by Lazaridou A, Peysakhovich A, Baroni M. arXiv, 2016.
- Learning to communicate to solve riddles with deep distributed recurrent q-networks by Foerster J N, Assael Y M, de Freitas N, et al. arXiv, 2016.
- Learning to communicate with deep multi-agent reinforcement learning by Foerster J, Assael Y M, de Freitas N, et al. NIPS, 2016.
- Learning multiagent communication with backpropagation by Sukhbaatar S, Fergus R. NIPS, 2016.
- Efficient distributed reinforcement learning through agreement by Varshavskaya P, Kaelbling L P, Rus D. Distributed Autonomous Robotic Systems, 2009.
7.10 Transfer Learning
- Simultaneously Learning and Advising in Multiagent Reinforcement Learning by Silva, Felipe Leno da; Glatt, Ruben; and Costa, Anna Helena Reali. AAMAS, 2017.
- Accelerating Multiagent Reinforcement Learning through Transfer Learning by Silva, Felipe Leno da; and Costa, Anna Helena Reali. AAAI, 2017.
- Accelerating multi-agent reinforcement learning with dynamic co-learning by Garant D, da Silva B C, Lesser V, et al. Technical report, 2015
- Transfer learning in multi-agent systems through parallel transfer by Taylor, Adam, et al. ICML, 2013.
- Transfer learning in multi-agent reinforcement learning domains by Boutsioukis, Georgios, Ioannis Partalas, and Ioannis Vlahavas. European Workshop on Reinforcement Learning, 2011.
- Transfer Learning for Multi-agent Coordination by Vrancx, Peter, Yann-Michaël De Hauwere, and Ann Nowé. ICAART, 2011.
7.11 Imitation and Inverse Reinforcement Learning
- Multi-Agent Adversarial Inverse Reinforcement Learning by Lantao Yu, Jiaming Song, Stefano Ermon. ICML 2019.
- Multi-Agent Generative Adversarial Imitation Learning by Jiaming Song, Hongyu Ren, Dorsa Sadigh, Stefano Ermon. NeurIPS 2018.
- Cooperative inverse reinforcement learning by Hadfield-Menell D, Russell S J, Abbeel P, et al. NIPS, 2016.
- Comparison of Multi-agent and Single-agent Inverse Learning on a Simulated Soccer Example by Lin X, Beling P A, Cogill R. arXiv, 2014.
- Multi-agent inverse reinforcement learning for zero-sum games by Lin X, Beling P A, Cogill R. arXiv, 2014.
- Multi-robot inverse reinforcement learning under occlusion with interactions by Bogert K, Doshi P. AAMAS, 2014.
- Multi-agent inverse reinforcement learning by Natarajan S, Kunapuli G, Judah K, et al. ICMLA, 2010.
7.12 Meta Learning
- Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments by l-Shedivat, M. 2018.
7.13 Application
- MAgent: A Many-Agent Reinforcement Learning Platform for Artificial Collective Intelligence by Zheng L et al. NIPS 2017 & AAAI 2018 Demo. (Github Page)
- Collaborative Deep Reinforcement Learning for Joint Object Search by Kong X, Xin B, Wang Y, et al. arXiv, 2017.
- Multi-Agent Stochastic Simulation of Occupants for Building Simulation by Chapman J, Siebers P, Darren R. Building Simulation, 2017.
- Extending No-MASS: Multi-Agent Stochastic Simulation for Demand Response of residential appliances by Sancho-Tomás A, Chapman J, Sumner M, Darren R. Building Simulation, 2017.
- Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving by Shalev-Shwartz S, Shammah S, Shashua A. arXiv, 2016.
- Applying multi-agent reinforcement learning to watershed management by Mason, Karl, et al. Proceedings of the Adaptive and Learning Agents workshop at AAMAS, 2016.
- Crowd Simulation Via Multi-Agent Reinforcement Learning by Torrey L. AAAI, 2010.
- Traffic light control by multiagent reinforcement learning systems by Bakker, Bram, et al. Interactive Collaborative Information Systems, 2010.
- Multiagent reinforcement learning for urban traffic control using coordination graphs by Kuyer, Lior, et al. oint European Conference on Machine Learning and Knowledge Discovery in Databases, 2008.
- A multi-agent Q-learning framework for optimizing stock trading systems by Lee J W, Jangmin O. DEXA, 2002.
- Multi-agent reinforcement learning for traffic light control by Wiering, Marco. ICML. 2000.
本文作者认为,多智能体强化学习算法在2021年前,只有QMix(基于Q值分解+DQN)和MAPPO(基于MADDPG提出的CTDE框架+PPO)这两个算法可信。其他MARL算法我只能当它们不存在。
8.分层强化学习 Hierarchical RL
神经网络有一个缺陷(特性):在数据集A上面训练的网络,拿到数据集B上训练后,这个网络会把数据集A学到的东西忘掉(灾难性遗忘 Catastrophic forgetting 1999)。如果我让智能体学游泳,再让它学跑步,它容易把游泳给忘了(人好像也这样,不够没有它那么严重)。深度学习领域有「迁移学习」、强化学习领域有「分层强化学习」在试图解决这些难题。
- FuNs,分级网络 FeUdal Networks ,分层强化学习不再用单一策略去解决这些更复杂的问题,而是将策略分为上层策略与多个下层策略 sub-policy 。上层策略会根据不同的状态决定使用哪个下层策略。它使用了同策路on-policy的A3C算法
- HIRO,使用异策略进行校正的分层强化学习 HIerarchical Reinforcement learning with Off-policy correction,警惕HIRO这个算法:FuN使用同策路on-policy的A3C算法,HIRO使用异策略off-policy的TD3算法,这个让我警惕:我个人认为不能像HIRO那样去使用TD3算法。
- Option-Critic,有控制权的下层策略,让将上层的策略和下层策略的控制权也当成是可以学习的,让下层的策略学习把“决定使用哪个策略的选择权”交还给上层策略的时机,这是一种隐式的分层强化学习方案,我没有复现过这个算法,我不确定这是否真的有效。
我不懂分层强化学习,请看别人写的 张楚珩:【强化学习算法 18】FuN ,张楚珩:【强化学习算法 19】HIRO ,张楚珩:【强化学习算法 20】Option-Critic
9.逆向强化学习 Inverse RL 与 模仿学习 Imitation Learning
强化学习会在回报函数 Reward function的指导下探索训练环境,并使用未来的期望收益来强化当前动作,试图求出更优的策略。然而,现实中不容易找到需要既懂任务又懂RL的人类去手动设计Reward function。
以 LunarLander为例子:降落+200 坠毁-100,消耗燃料会扣0~100。其实只有这些我们也能用很长的时间训练得到能安全降落的飞行器。但实际上,我们还可以根据飞行器的平稳程度给它每步一位数的奖惩,根据飞行器距离降落点的距离给他额外的奖励。这些很细节的调整可以减少智能体的训练时间。所以我前面建议:如果训练环境 Reward function 都是初学者写的,那就用PPO。等到 Reward function 设计得更合理之后,才适合用SAC。
- 强化学习:训练环境+DRL算法+Reward Function = 搜索出好的策略
- 逆向强化学习:训练环境+IRL算法+好的策略 = 逆向得到Reward Function
逆向强化学习为了解决这个问题,提出:通过模仿好的策略 去反向得到 Reward function。我不懂逆向强化学习,如果强行写解释也只能翻译其他人的综述:A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress
10.基于模型的强化学习算法 Model-based RL(重点介绍MuZero)
这里的「模型」指:状态转移模型。离散状态空间下的状态转移模型可以用 状态转移矩阵去描述。基于模型的算法需要将状态转移模型探索出来(或由人类提供),而 无模型算法 model-free RL 不需要探索出模型,它仅依靠智能体在环境中探索 rollout 得到的一条条 trajectory 中记录的 environment transition (s, a, r, next state) 即可对策略进行更新。
我对无模型算法不够了解,如果强行写解释也只能翻译其他人的综述:Model-based Reinforcement Learning: A Survey 。OpenAI 提供了一些简单的代码: SpinningUp Model-based RL 。
近年来受到最多圈外人关注的 model-based RL 是 MuZero。在下棋、雅达利游戏这种状态转移模型相对容易拟合的离散动作空间任务中,MuZero取得了非常不错的表现。它有三个网络:
- 编码器:输入连续观测到的几个state,将其编码成 latent state。为何非要使用 latent state 而不直接使用 state? 在当前state 下做出action 后,并不会转移到某个确切的状态,next state 是一个不容易直接描述的分布。因此接下来的生成器不会(也无法)直接预测 next state,只能预测 latent state。
- 预测器:输入当前观测到的state,生成执行每个动作的概率,并预测执行每个动作的value (Q值,我不反对将它粗略地理解为DQN的 Q Network)。
- 生成器:输入当前观测到的state,生成 执行每个离散动作后会转移到的 latent state 以及对应的 Reward(这是单步的Reward,不是累加得到的Q值)。生成器就是MuZero 这个model-based RL算法 学到的状态转移模型。
如果离散动作的数量很多(如围棋),那么MuZero 会使用MCTS(Monte Carlo tree search 蒙特卡洛树搜索),剪除低概率的分支并估计Q值(论文里用 ),具体剪去多少分支要看有多少算力和时间。
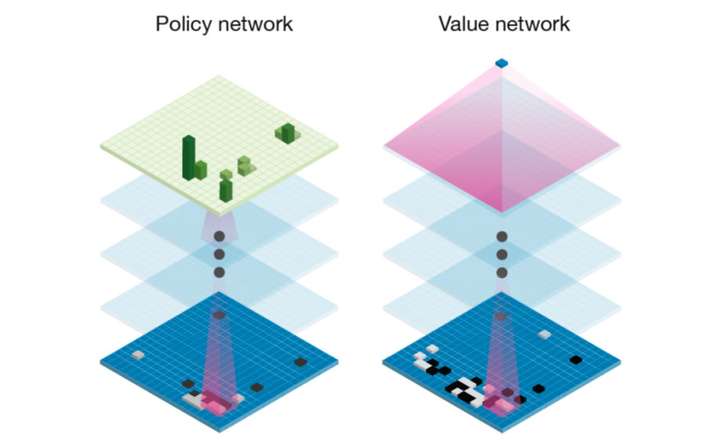 图中左上角绿色的柱子是离散动作执行概率,可以看到:虽然围棋有很多位置可下,但实际上只有几个位置能下出好棋。如果对面不是柯洁,那么一些分支可以剪除不去计算它。
图中左上角绿色的柱子是离散动作执行概率,可以看到:虽然围棋有很多位置可下,但实际上只有几个位置能下出好棋。如果对面不是柯洁,那么一些分支可以剪除不去计算它。
剪枝:蒸馏学习的 Weight Pruning 权重剪枝,消除权重中不必要的值。在MCTS中的剪枝是不计算执行概率过低的动作分支。
model-based RL 学到状态转移模型之后,就能在探索环境之前想象出接下来几步的变化,然后基于环境模型做规划,减少与环境的交互次数。(在model-based RL 中经常可以读到 Imagination,planning,dream这些词)。这里顺便解释一下 MuZero 的 Mu 是什么意思? 解释来自MuZero Intuition - Julian Schrittwieser - What’s in a name?
- 希腊字母 μ,用来表示强化学习算法学到的策略模型
- 夢(梦)。MuZero使用预测器预测智能体在环境中的下一步。
- 無(无)。MuZero(AlphaZero)不需要像前身AlphaGo 那依赖人类知识去学习。
推荐看知乎问题:如何评价DeepMind新提出的MuZero算法? 下面的 什么名字可以吸粉的回答(他的翻译比较好:representation function 编码器,prediction function 预测器,dynamics function 生成器) 与 Evensgn的回答 (Value Prediction Network 值得看一看)。
11.会议&期刊
会议
AAAI、NIPS、ICML、ICLR、IJCAI、AAMAS、IROS等
期刊
AI、JMLR、JAIR、Machine Learning、JAAMAS等
计算机和人工智能会议(期刊)排名
清华发布新版计算机学科推荐学术会议和期刊列表,与CCF有何不同?
https://www.aminer.cn/ranks/conf/artificial-intelligence-and-pattern-recognition
12.公众号
深度强化学习实验室、机器之心、AI科技评论、新智元、学术头条
13.知乎
大牛
田渊栋、Flood Sung、许铁-巡洋舰科技(微信公众号同名)、
周博磊、俞扬、张楚珩、天津包子馅儿、JQWang2048 及其互关大牛等
专栏
- David Silver强化学习公开课中文讲解及实践(叶强,比较经典)
- 强化学习知识大讲堂(《深入浅出强化学习:原理入门》作者天津包子馅儿)
- 智能单元(杜克、Floodsung、wxam,聚焦通用人工智能,Flood Sung:深度学习论文阅读路线图 Deep Learning Papers Reading Roadmap很棒,Flood Sung:最前沿:深度强化学习的强者之路)
- 深度强化学习落地方法论(西交 大牛,实操经验丰富)
- 深度强化学习(知乎:JQWang2048,GitHub:NeuronDance,CSDN:J. Q. Wang)
- 神经网络与强化学习(《Reinforcement Learning: An Introduction》读书笔记)
- 强化学习基础David Silver笔记(陈雄辉,南大,DiDi AI Labs)
14. 官网
OpenAI
DeepMind
Berkeley Artificial Intelligence Research
以及Sutton老爷子、Andrew NG、David Silver、Pieter Abbeel、John Schulman、Sergey Levine、Chelsea Finn、Andrej Karpathy等主页
15.环境及框架
OpenAI Gym (GitHub) (docs)
rllab (GitHub) (readthedocs)
Ray (Doc)
Dopamine: https://github.com/google/dopamine (uses some tensorflow)
trfl: https://github.com/deepmind/trfl (uses tensorflow)
ChainerRL (GitHub) (API: Python)
Surreal GitHub (API: Python) (support: Stanford Vision and Learning Lab).Paper
PyMARL GitHub (support: http://whirl.cs.ox.ac.uk/)
TF-Agents: https://github.com/tensorflow/agents (uses tensorflow)
TensorForce (GitHub) (uses tensorflow)
RL-Glue (Google Code Archive) (API: C/C++, Java, Matlab, Python, Lisp) (support: Alberta)
MAgent https://github.com/geek-ai/MAgent (uses tensorflow)
RLlib http://ray.readthedocs.io/en/latest/rllib.html (API: Python)
http://burlap.cs.brown.edu/ (API: Java)
rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
robotics-rl-srl - S-RL Toolbox: Reinforcement Learning (RL) and State Representation Learning (SRL) for Robotics
OpenAI universe - A software platform for measuring and training an AI’s general intelligence across the world’s supply of games, websites and other applications
DeepMind Lab - A customisable 3D platform for agent-based AI research
Project Malmo - A platform for Artificial Intelligence experimentation and research built on top of Minecraft by Microsoft
Retro Learning Environment - An AI platform for reinforcement learning based on video game emulators. Currently supports SNES and Sega Genesis. Compatible with OpenAI gym.
torch-twrl - A package that enables reinforcement learning in Torch by Twitter
UETorch - A Torch plugin for Unreal Engine 4 by Facebook
TorchCraft - Connecting Torch to StarCraft
rllab - A framework for developing and evaluating reinforcement learning algorithms, fully compatible with OpenAI Gym
TensorForce - Practical deep reinforcement learning on TensorFlow with Gitter support and OpenAI Gym/Universe/DeepMind Lab integration.
OpenAI lab - An experimentation system for Reinforcement Learning using OpenAI Gym, Tensorflow, and Keras.
keras-rl - State-of-the art deep reinforcement learning algorithms in Keras designed for compatibility with OpenAI.
BURLAP - Brown-UMBC Reinforcement Learning and Planning, a library written in Java
MAgent - A Platform for Many-agent Reinforcement Learning.
Ray RLlib - Ray RLlib is a reinforcement learning library that aims to provide both performance and composability.
SLM Lab - A research framework for Deep Reinforcement Learning using Unity, OpenAI Gym, PyTorch, Tensorflow.
Unity ML Agents - Create reinforcement learning environments using the Unity Editor
Intel Coach - Coach is a python reinforcement learning research framework containing implementation of many state-of-the-art algorithms.
ELF - An End-To-End, Lightweight and Flexible Platform for Game Research
https://github.com/Unity-Technologies/ml-agents (Unity, multiagent)
https://github.com/koulanurag/ma-gym (multiagent)
https://github.com/Phylliade/awesome-openai-gym-environments
https://github.com/deepmind/pysc2 (by DeepMind) (Blizzard StarCraft II Learning Environment (SC2LE) component)
好用的强化学习算法
- 没有很多需要调整的超参数。D3QN、SAC超参数较少,且SAC可自行调整超参数
- 超参数很容易调整或确定。SAC的 reward scaling 可以在训练前直接推算出来。PPO超参数的细微改变不会极大地影响训练
- 训练快,收敛稳、得分高。看下面的学习曲线 learning curve
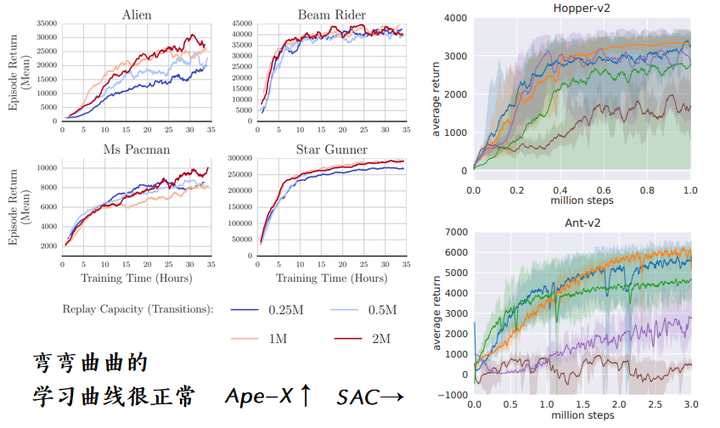 弯弯曲曲的学习曲线很正常,图片截取自 Ape-X 与 SAC 论文
弯弯曲曲的学习曲线很正常,图片截取自 Ape-X 与 SAC 论文
学习曲线怎么看?
- 横轴可以是训练所需的步数(智能体与环境交互的次数)、训练轮数(达到固定步数、失败、通关 就终止终止这一轮的训练episode)、训练耗时(这个指标还与设备性能有关)
- 纵轴可以是 每轮得分( 每一轮的每一步的reward 加起来,episode return),对于没有终止状态的任务,可以计算某个时间窗口内reward之和
- 有时候还有用 plt.fill_between 之类的上下std画出来的波动范围,用于让崎岖的曲线更好看一点:先选择某一段数据,然后计算它的均值,再把它的标准差画出来,甚至可以画出它的上下偏差(琴形图)。如果同一个策略在环境随机重置后得分相差很大,那么就需要多测几次。
好的算法的学习曲线应该是?
- 训练快,曲线越快达到某个目标分数 target reward (需要多测几次的结果才有说服力)
- 收敛稳,曲线后期不抖动(曲线在前期剧烈抖动是可以接受的)
- 得分高,曲线的最高点可以达到很高(即便曲线后期下降地很厉害也没关系,因为我们可以保存整个训练期间“平均得分”最高的模型)
未来的工作方向
所以当下有两条路建议选择:一是去腾讯AIlab、华为诺亚、网易伏羲或者阿里研究型项目,二是去其他高校有积淀的实验室。这两种方式都蛮不错的,应该会比自己闭门造车的速度快。只不过,这些地方的要求都不会低,想要去做科研要好好准备面试。



