名词解释:Meta Learning = Learn to learn ,也就是学习如何学习。和机器学习不同,这个是另外一个层次的东西了。
在我们深度学习领域,其实大多数时候都是在调超参数(hyperparameters),在工业届的做法是一次性使用上万张显卡使用多个hyperparameters同时训练多个模型,然后挑选训练得好的。但是在学术界并没有这么多设备,往往依靠个人的经验来调整hyperparameters。那么这种超参数能不能让机器自己学习呢?

流程
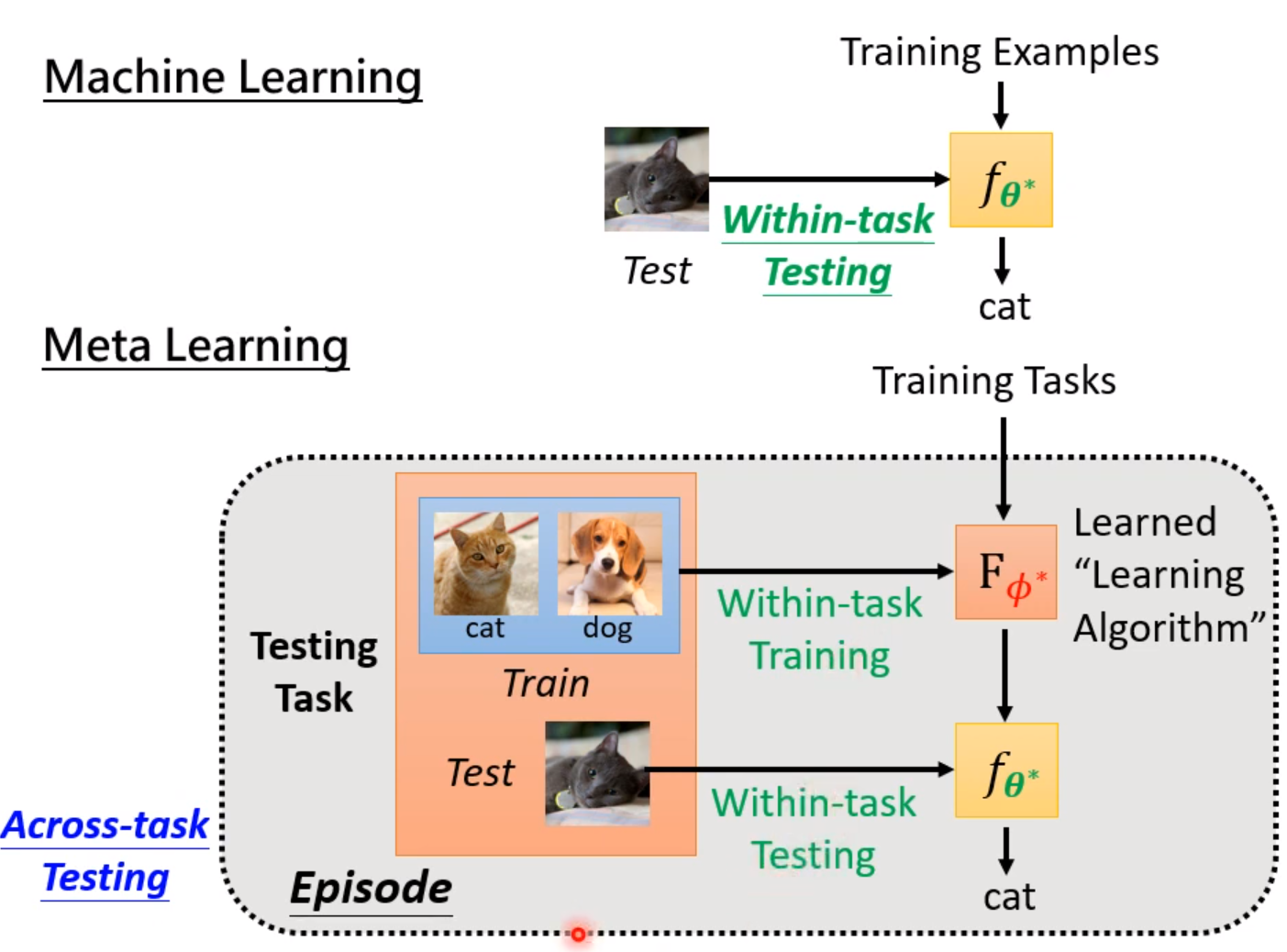
和机器学习类似,元学习也是通过训练资料来进行训练,但是训练目标是找出一个学习算法。我们期待诸如学习率这样的超参数是可以被学习出来的。不同的元学习的方法就是用来学习不同的超参数的。

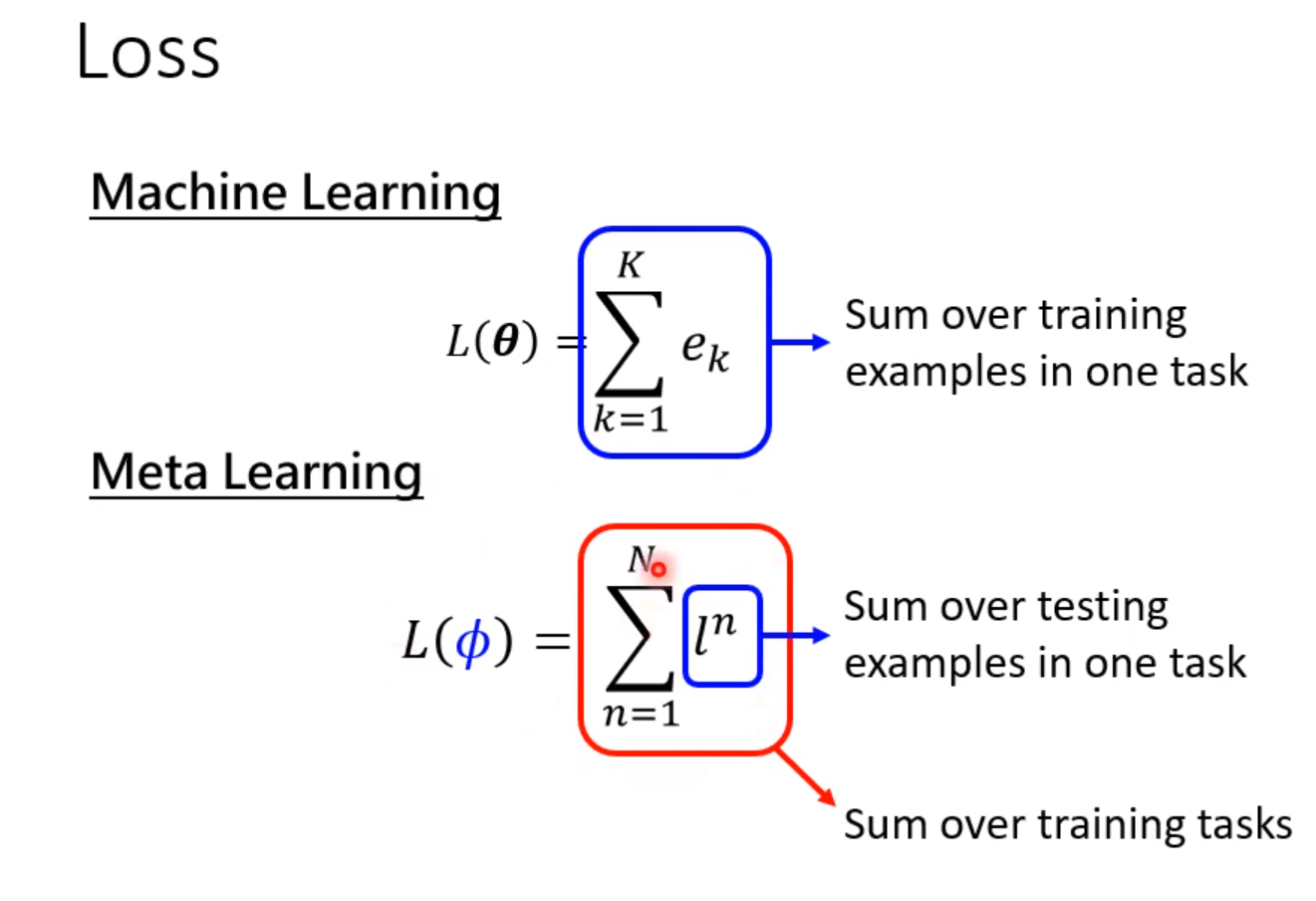
下面我们需要定义一个Loss函数来评价学习算法的优越程度。在深度学习中,我们使用收集到的资料来计算Loss。而在元学习中,我们使用收集到的任务,每个任务都有训练资料和测试资料。
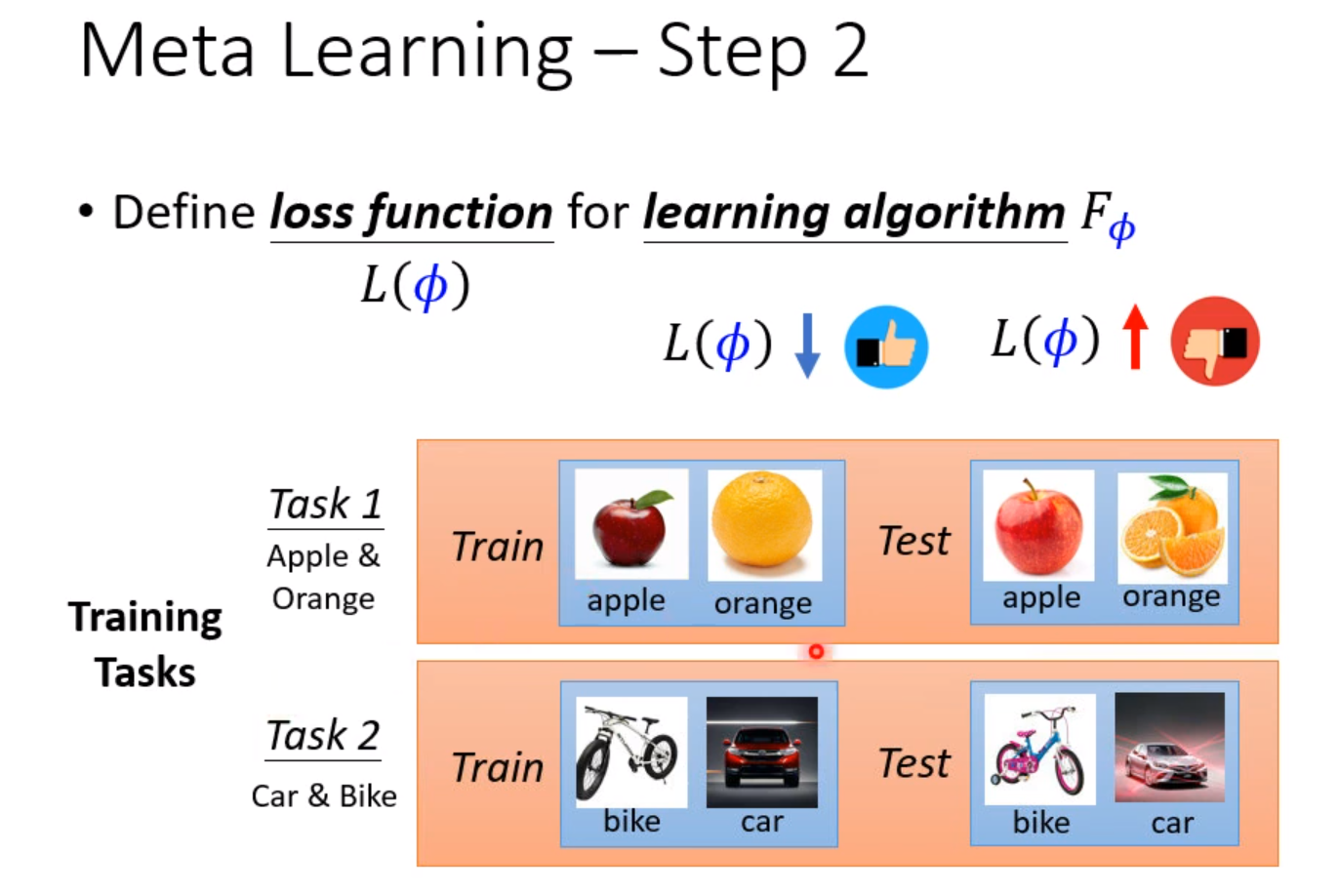
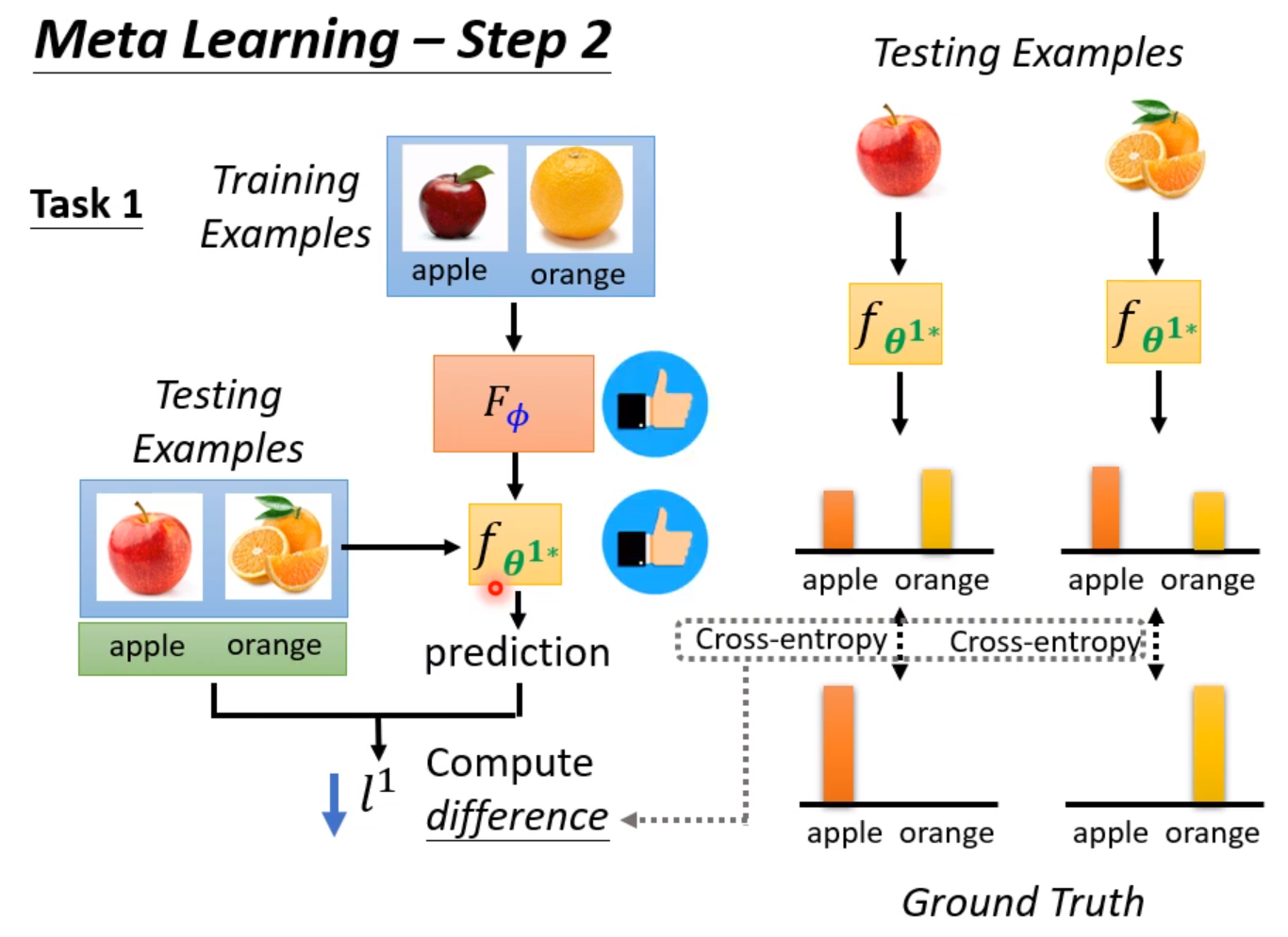
首先我们把训练集导入模型中进行训练,训练的效果就可以直接反应超参数的好坏。训练完成后,使用测试集进行测试。把模型的输出和实际的输出做Cross-entropy,这个值直接当做Loss,这个值越大,说明模型训练得越差,说明使用超参数是一个比较不好的超参数。越小说明训练得越好,超参数越棒。实际上我们不会只用一个任务来测试,往往会使用多个任务,然后把Loss相加,取平均值。
注意这里元学习和深度学习不同之处在于,Loss的计算元学习是使用了测试集的资料的。因为这里我们训练的单位是任务,所以可以使用训练任务中的测试集。
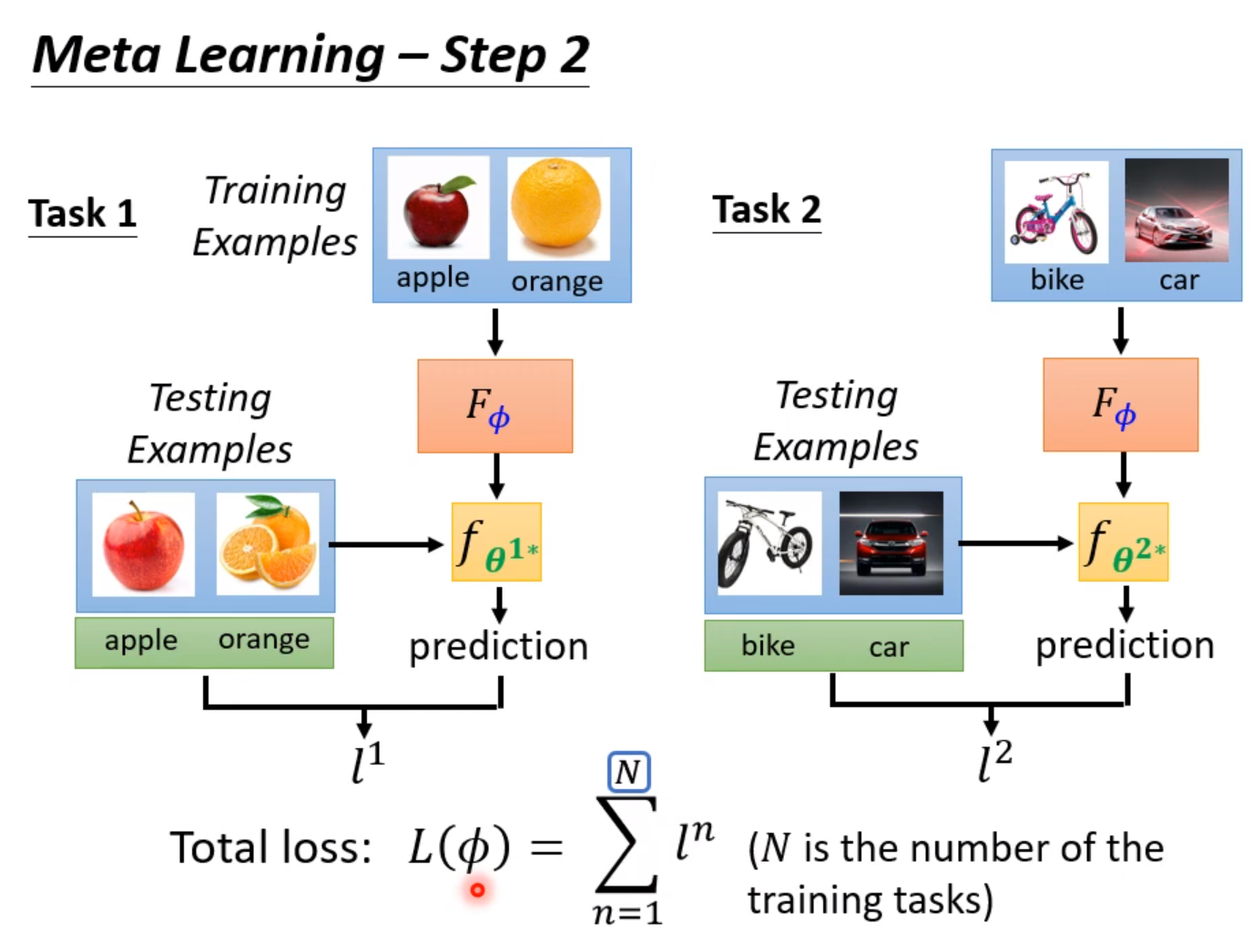
接下来的任务就是解这个最优化问题,找一个最优的超参数。而很多时候我们的超参数是不能用梯度下降法求解的,这时候可以尝试使用RL硬做。
总之,现在你通过学习算法找出来一个超参数。这时候可以进行测试了,这时候我们用到的数据集叫做测试任务,里面同样有训练集和测试集,我们可以直接把测试任务中的训练集倒进模型进行训练,然后用测试任务中的测试集进行测试,确定模型的优越性,同时也反应了超参数的优越性。
其实Meta Learning也需要调节超参数,等于是为了得到一个不用调超参数的模型,我们要训练另一个需要调超参数模型。
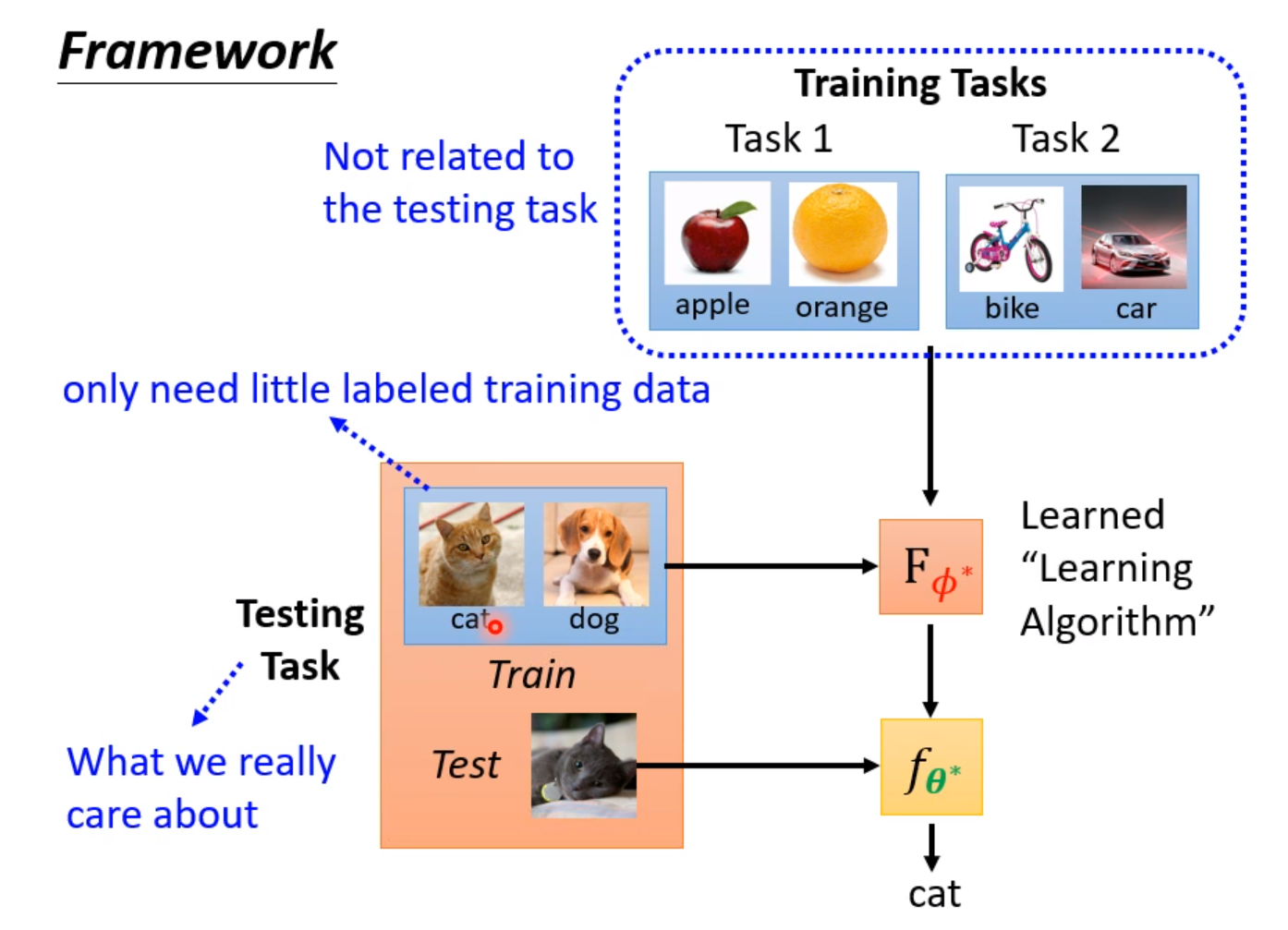
ML和Meta Learning的区别
下面是比较ML和meta Learning的区别。ML的目标是找一个函数,而Meta Learning更像是找一个能找函数的函数。而且使用数据集的形式也有所不同。Meta Learning是一种跨任务的学习。
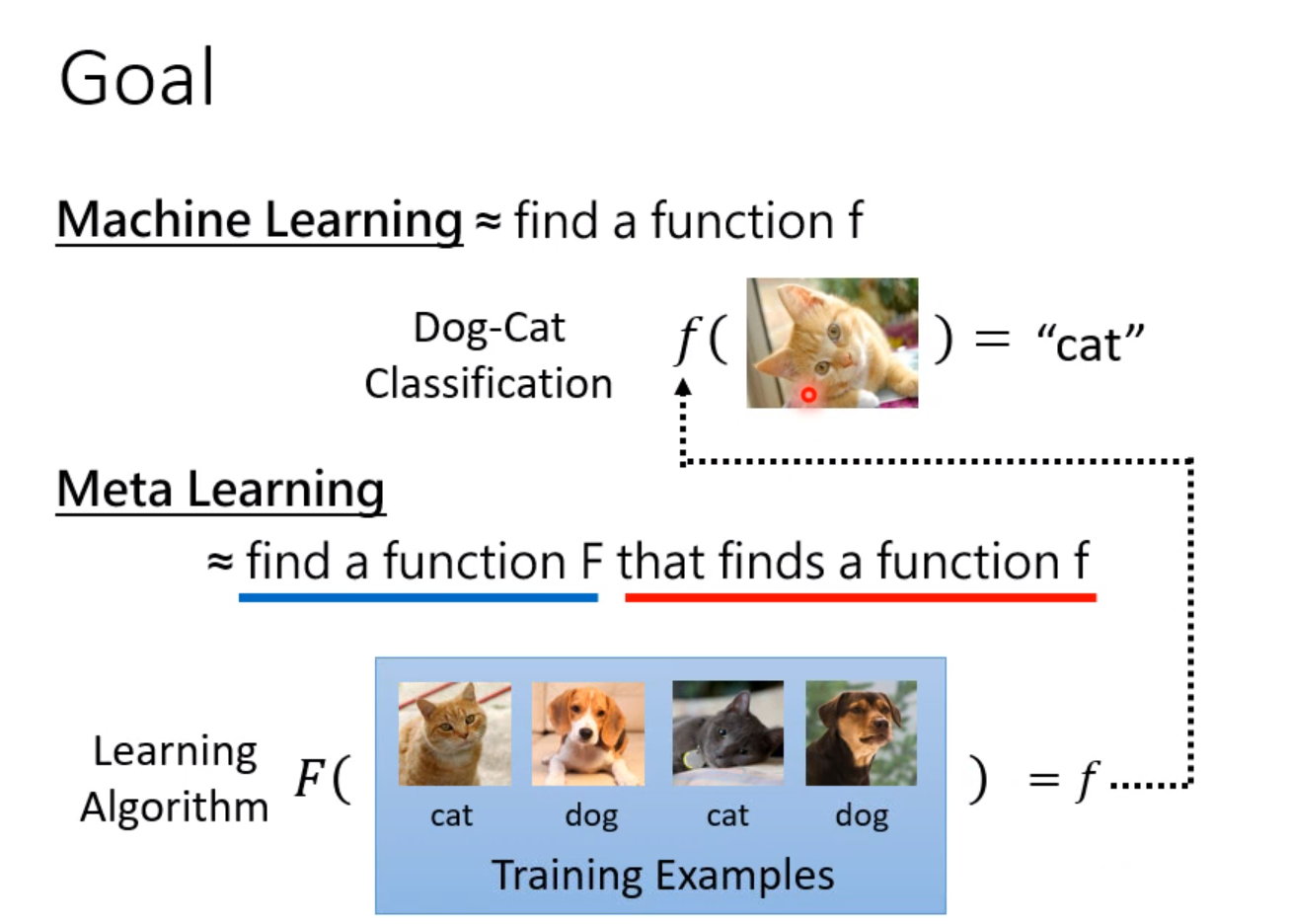
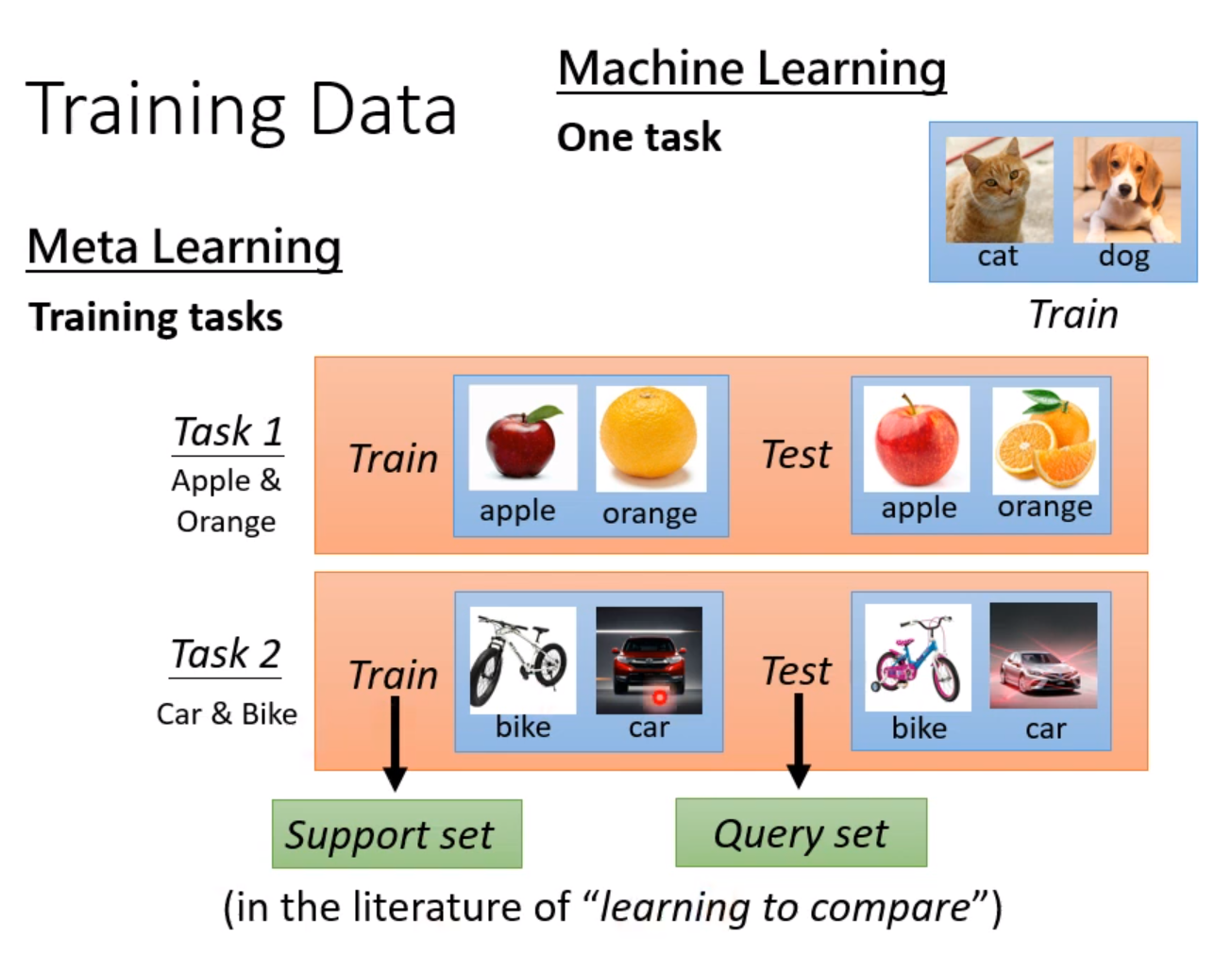
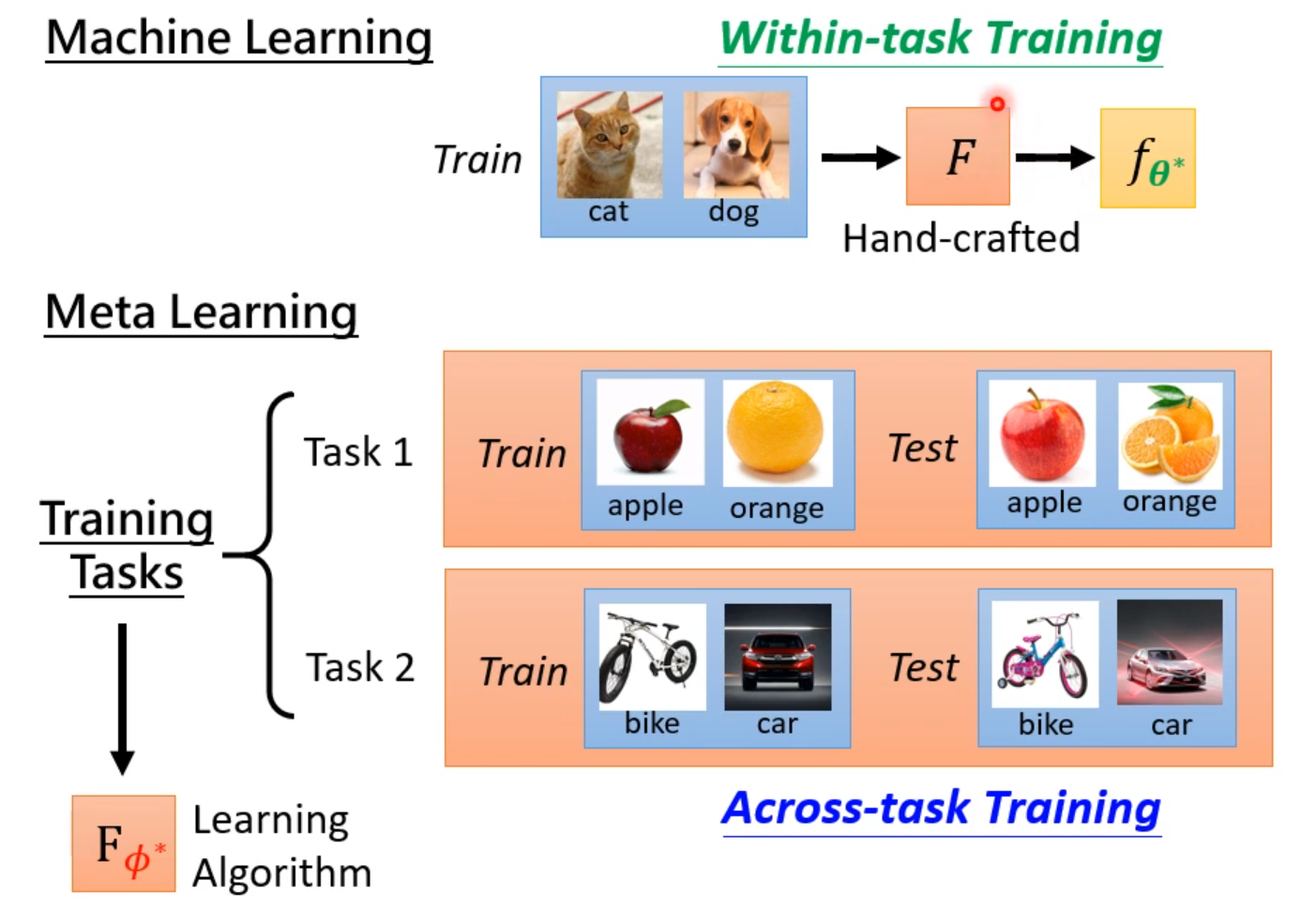
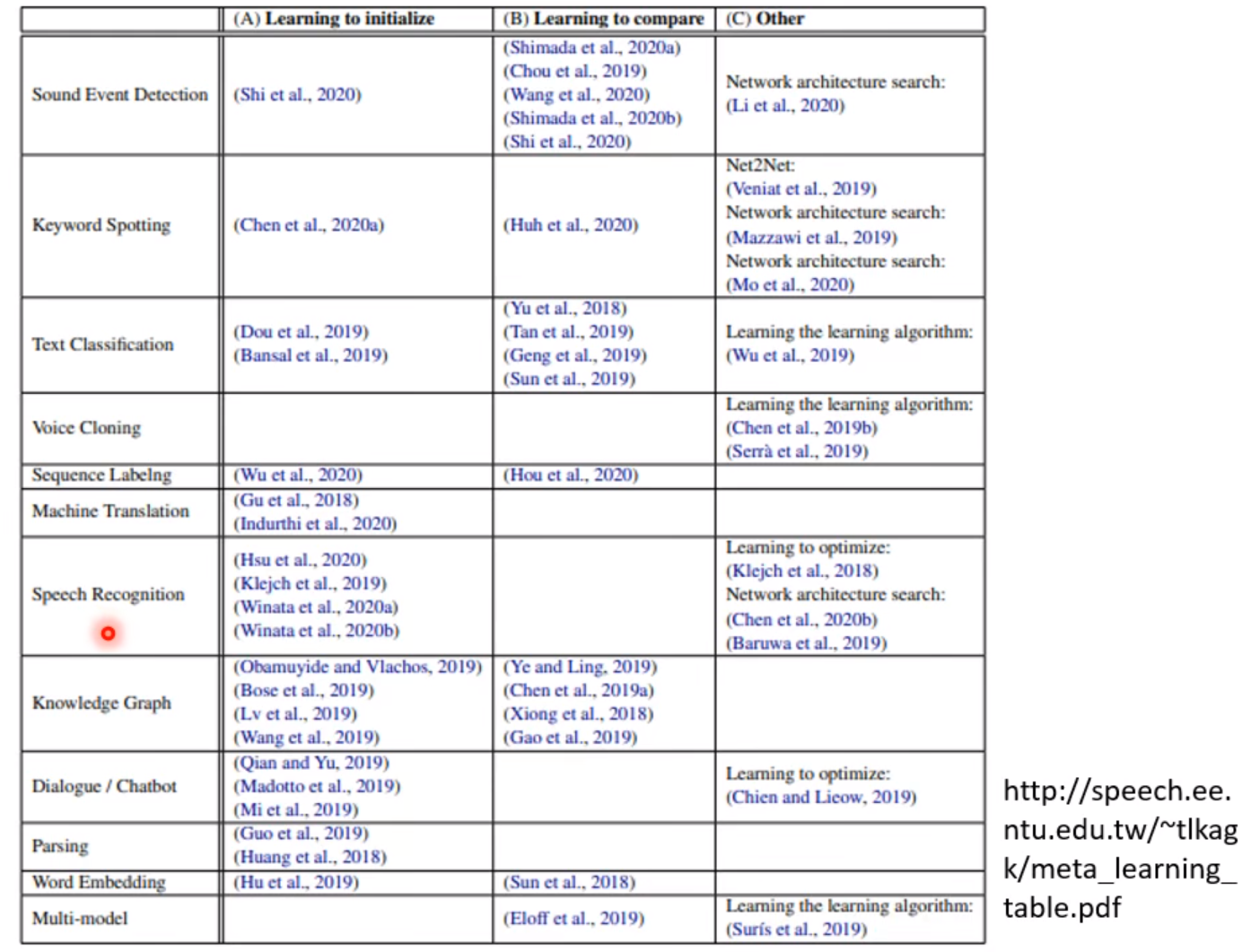
万物皆可Meta
训练初始化参数
当我们训练一个模型时,初始的参数往往非常重要,初始的参数好不好往往造成的训练效果天差地别,在Meta-Learning中就有这种选择较好的初始化参数的方法,具体内容可以自行查看论文:



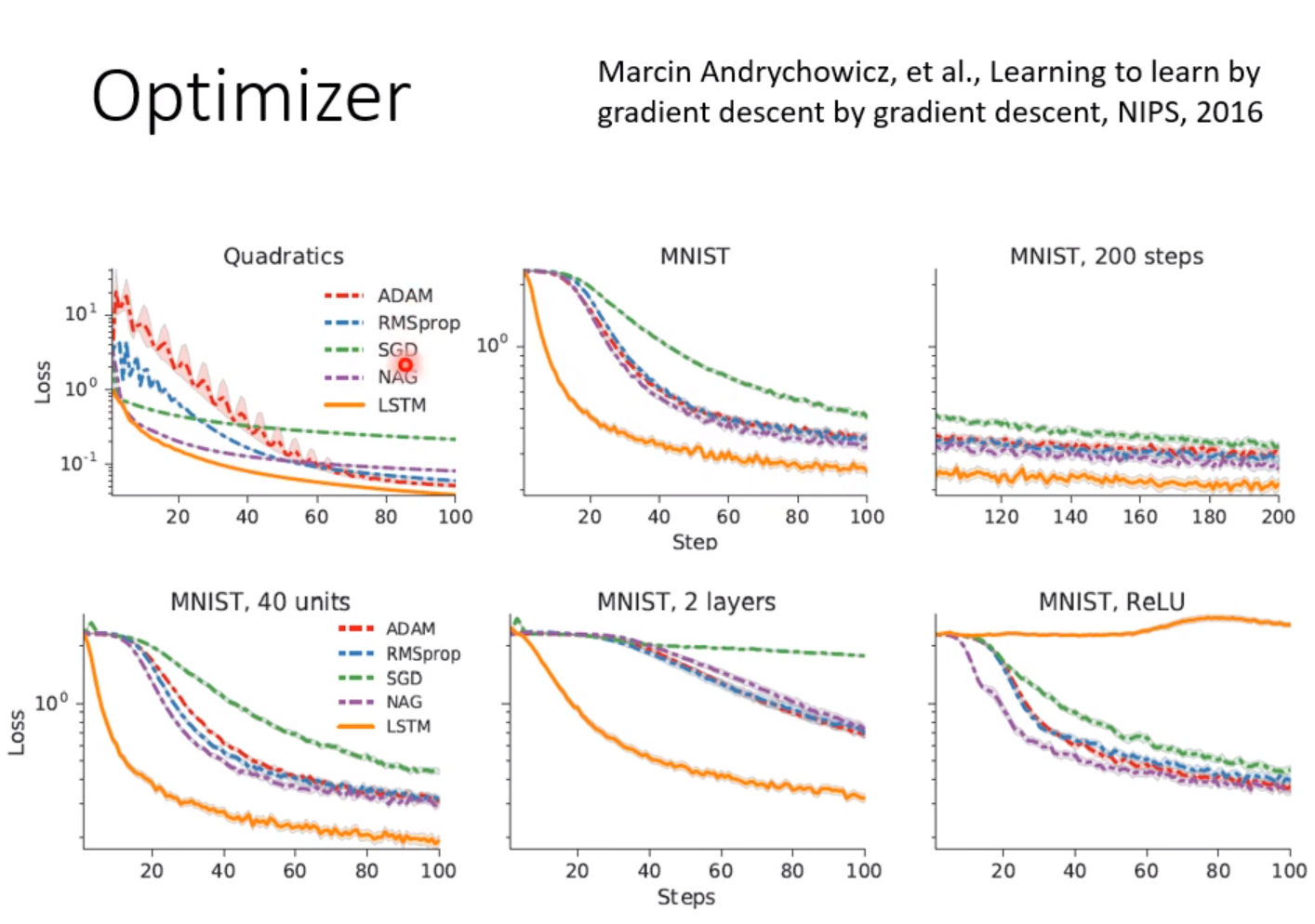
训练优化器(Optimizer)
训练Network架构
直接使用RL:


使用遗传算法:

把架构变得可以微分:

训练数据处理方式
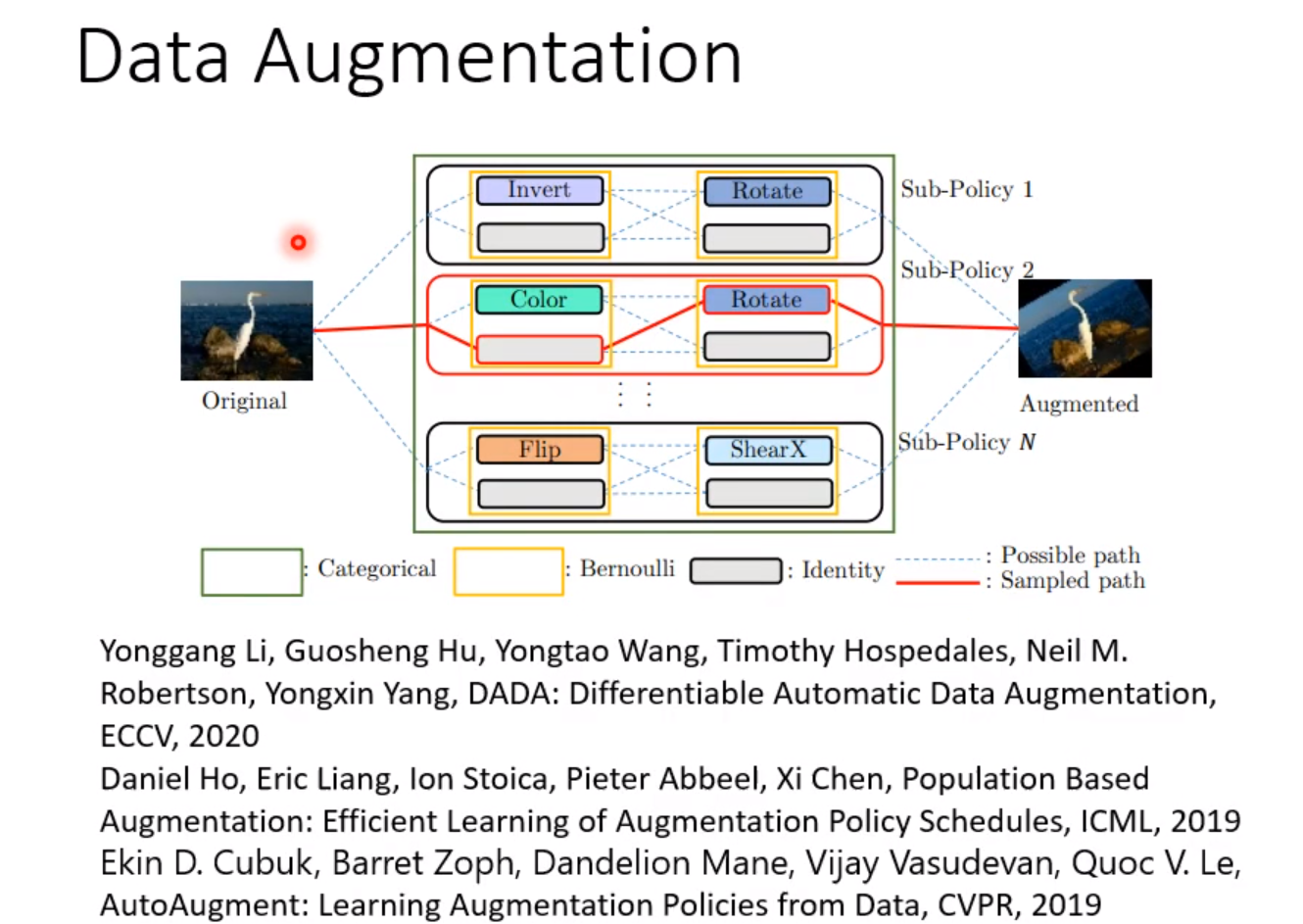
训练Sample Reweighting

舍弃Gradient Descent

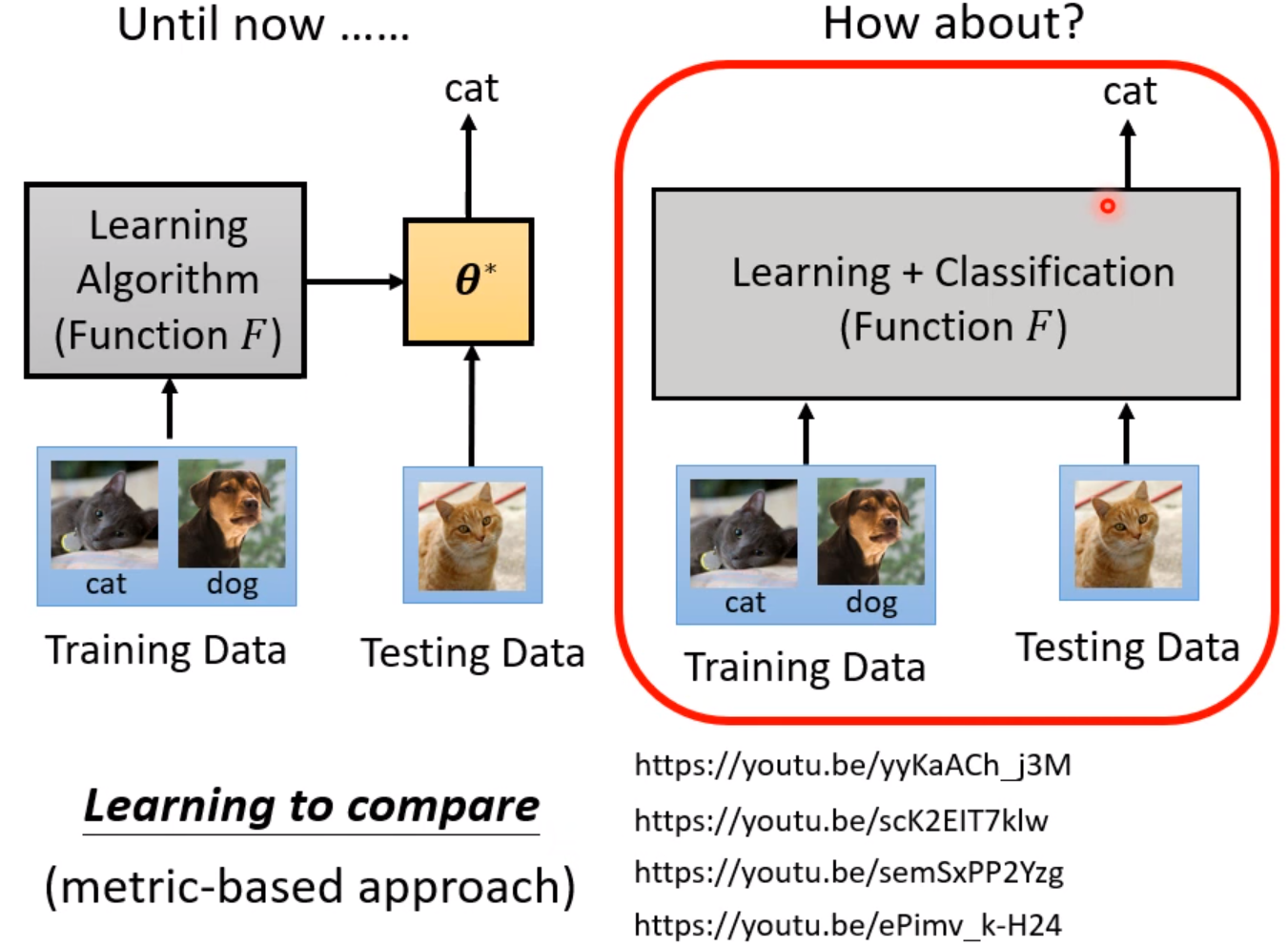
Learning to compare
我们可以使用一个Network同时读进训练资料和测试资料,输出测试资料的结果。
实际应用
通常我们可以把Meta-Learning用在few-shot learning上,我们只有很少的资料。