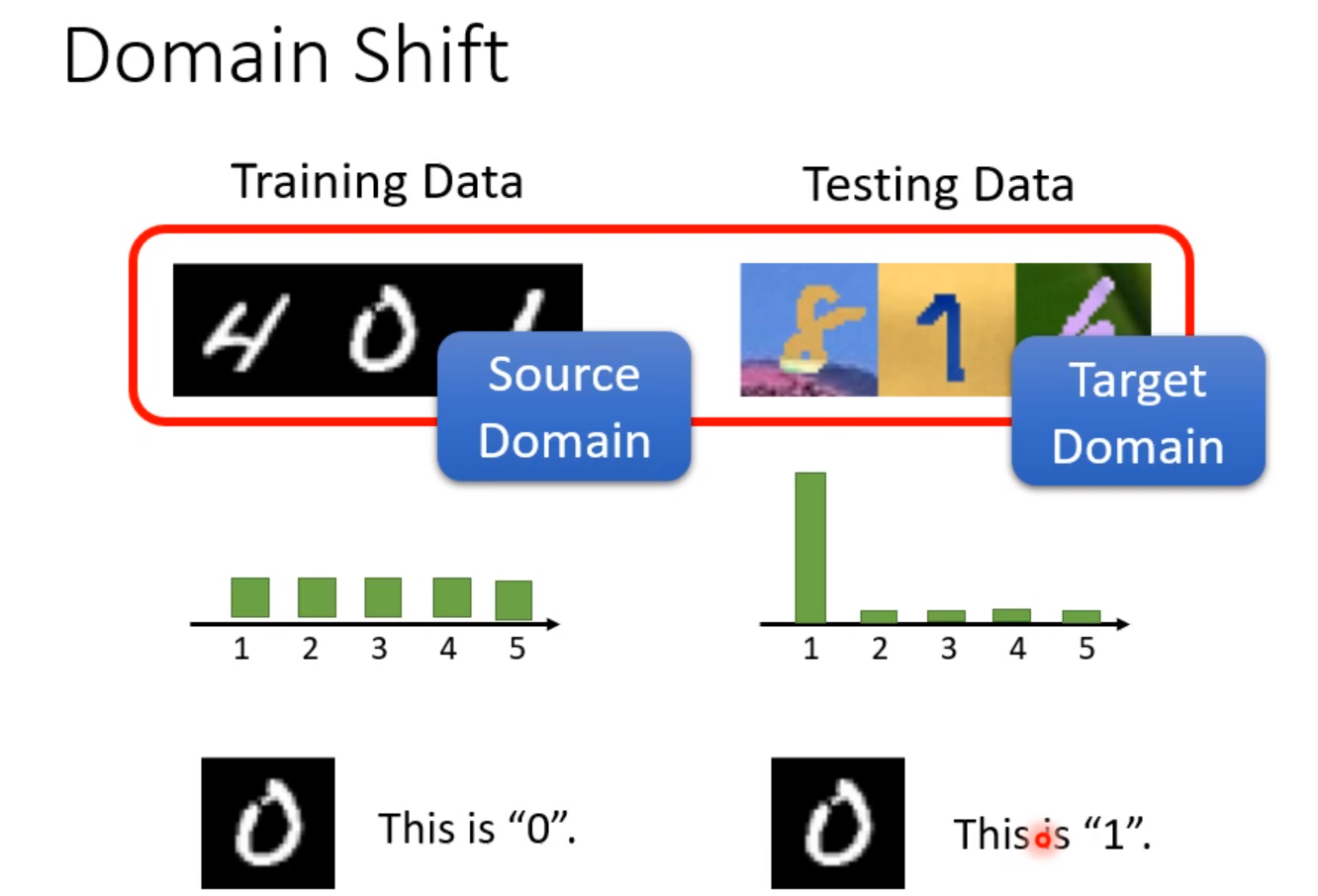
当训练和测试资料的分布不一样,得到的正确率将大大减小。当训练资料和测试资料分布不同的时候,这种状况叫做Domain-shift。在日常任务中测试资料和训练资料的分布通常并不相同。

Transfer-learning就是在A任务上学到的技能能够用在B任务上。除了输入的分布有变化,输出的分布也可能有变化,例如在有些事情上每一个数字的概率不是一样的,对应的方式也不一定一样。但现在我们只专注于输入的分布变化的情况。
当我们拥有大量的有标注的测试集资料,我们直接拿来训练就好。当我们只有少量的有标注的测试集资料时,处理的方式是用测试集资料对已经训练好的模型进行微调。但由于资料过少,我们不能训练太多的Iteration。否则容易overfitting。
但是往往的情景是我们有大量的测试集资料,但是这些资料都是没有标注的。这时候我们需要一个Feature-Extractor,使得原来的训练集的资料和测试集的资料映射到同一个分布上。

这样我们就可以把网络分成Feature-Extractor和Label-Predictor两部分。我们的要求是两种数据在经过Feature-Extractor后都分不出差异,例如形成的二维坐标系上的点的分布一样。具体做法类似GAN,训练一个Domain-Classifier对这两种图片进行分类,并让它们进行对抗,直到Domain-Classifier分不出两种图片的区别为止。
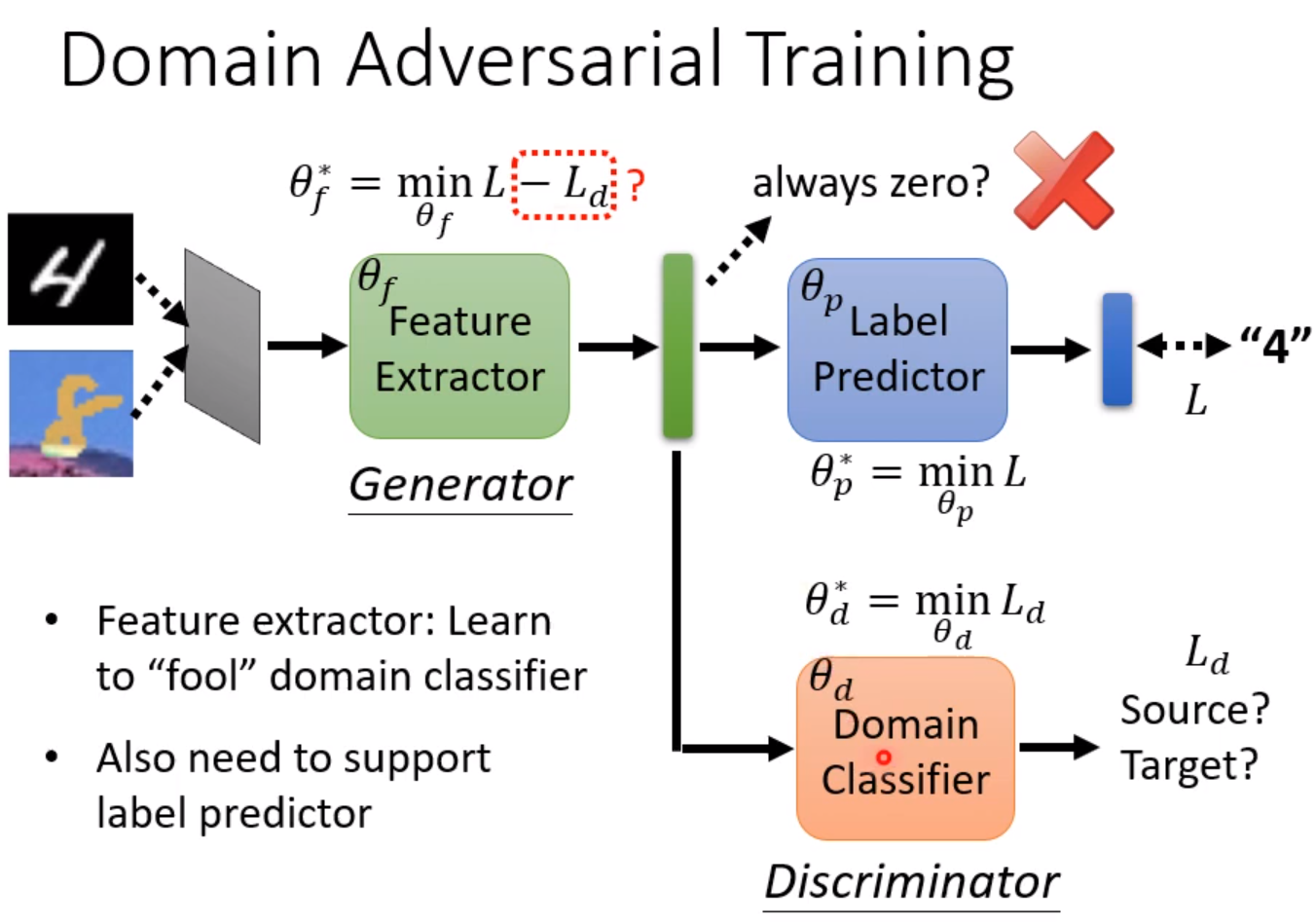
但这未必设最好的做法,因为Feature-Extractor和Domain-Classifier的作用实际上都是把两种domain分开。
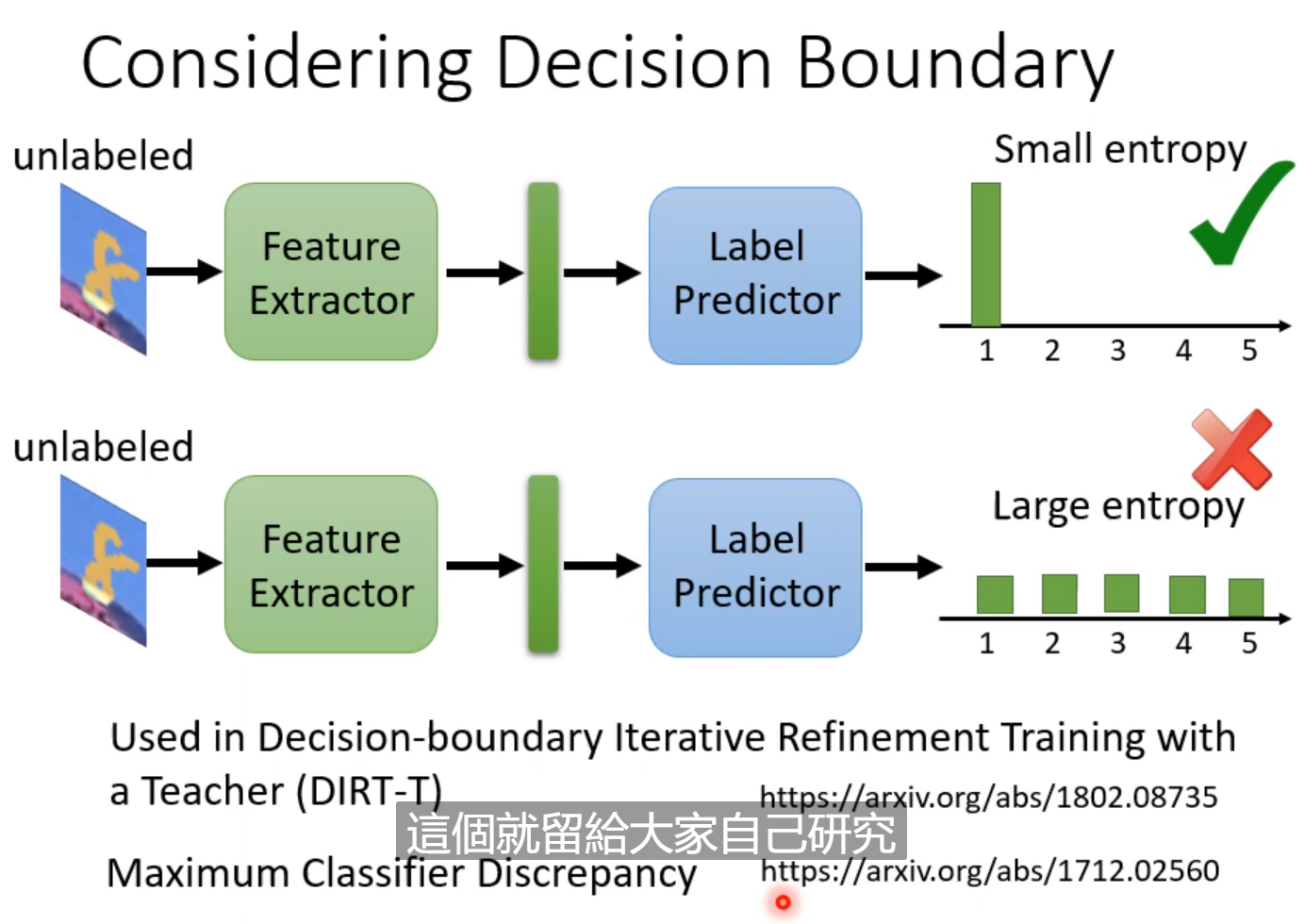
我们希望测试集的图片经过分类后,减少不确定性,能够很确定自己的分类,这样的结果是比较好的。具体的自行研究。
有的时候,两个Domain之间不一定拥有一样的类别,包含的类别可能交叉或者是包含关系,这样上面的方法就不适用了,因为类别的数量的不一致,强行要求数量上的一致显得不太合理,解决方法见图中文章。

上面的情况是基于有大量的未标注数据的情况下的,如果这种为标注的数据很少,有一种方法是Testing-Time-Training。论文如下:

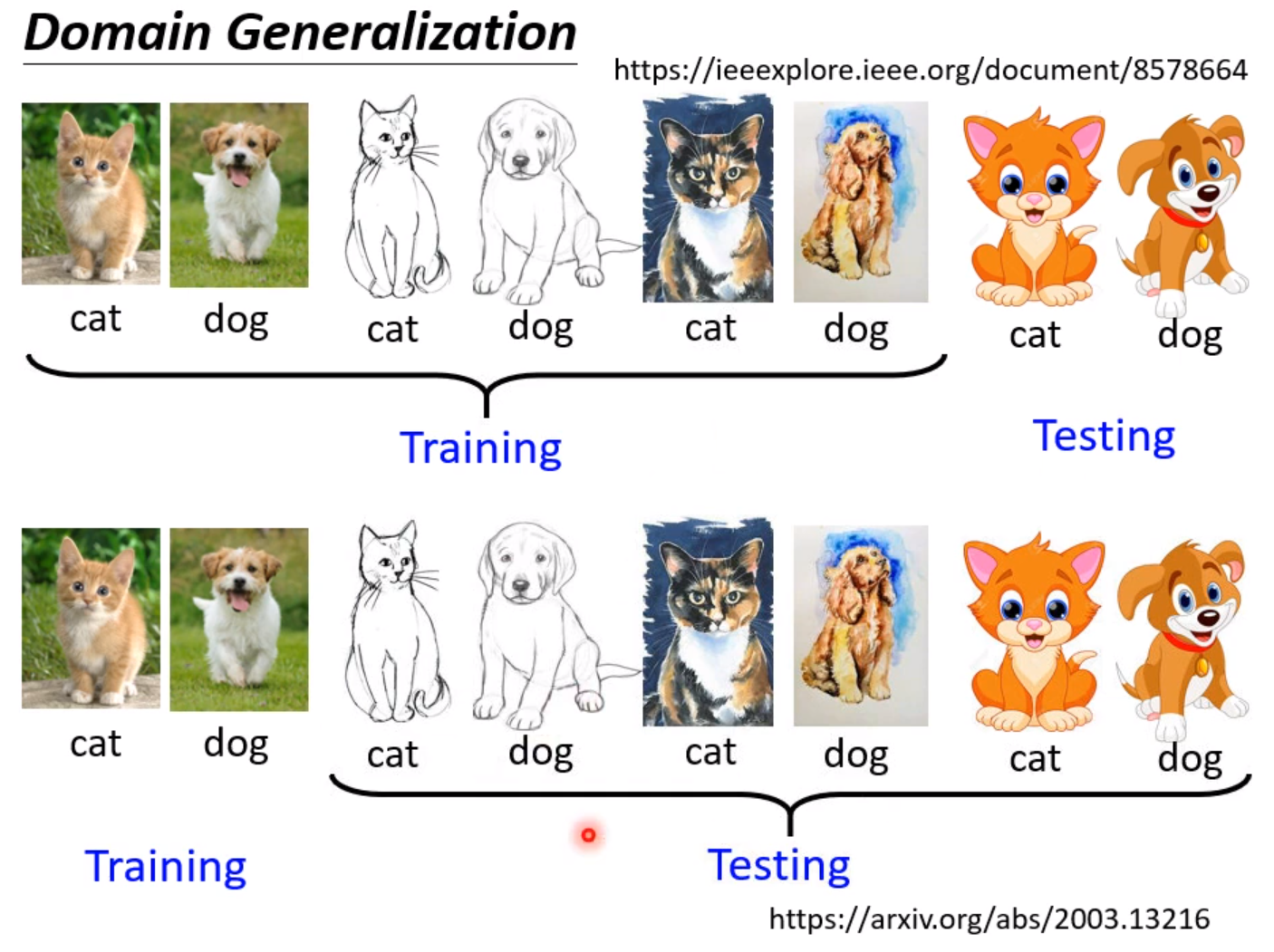
还有一种更为严峻的情况,就是我们对新的Domain一无所知,这叫做Domain-Generalization。