攻击方式
一个模型想要实际应用,不仅仅需要较高的准确率,还需要能应对人类的恶意攻击。例如分辨垃圾邮件,发件方也会尽量让邮件看起来不像垃圾邮件。又例如在图片中加入一些噪声,模型要想办法让噪声也不影响输出。
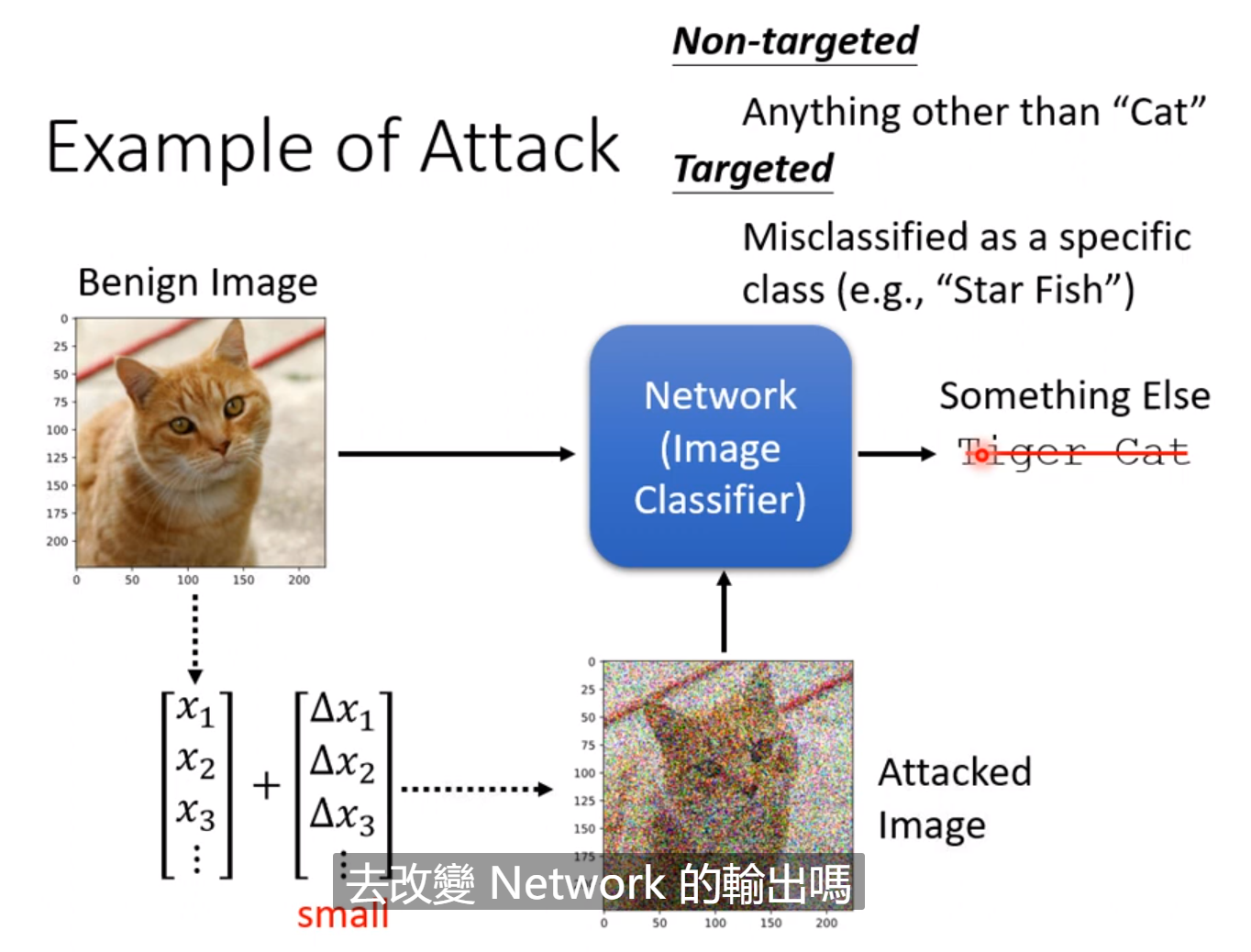

有时候即使是人肉眼难以分辨的微小噪声,也能使得输出天差地别。这种攻击的做法就是找到一张新的图片输入到模型中,使得输出根正确答案差距越大越好。如果是有目标的攻击,我们不仅要让输出远离正确答案,还要靠近我们想要的答案。而这张新的图片我们希望加入的噪声越小越好。
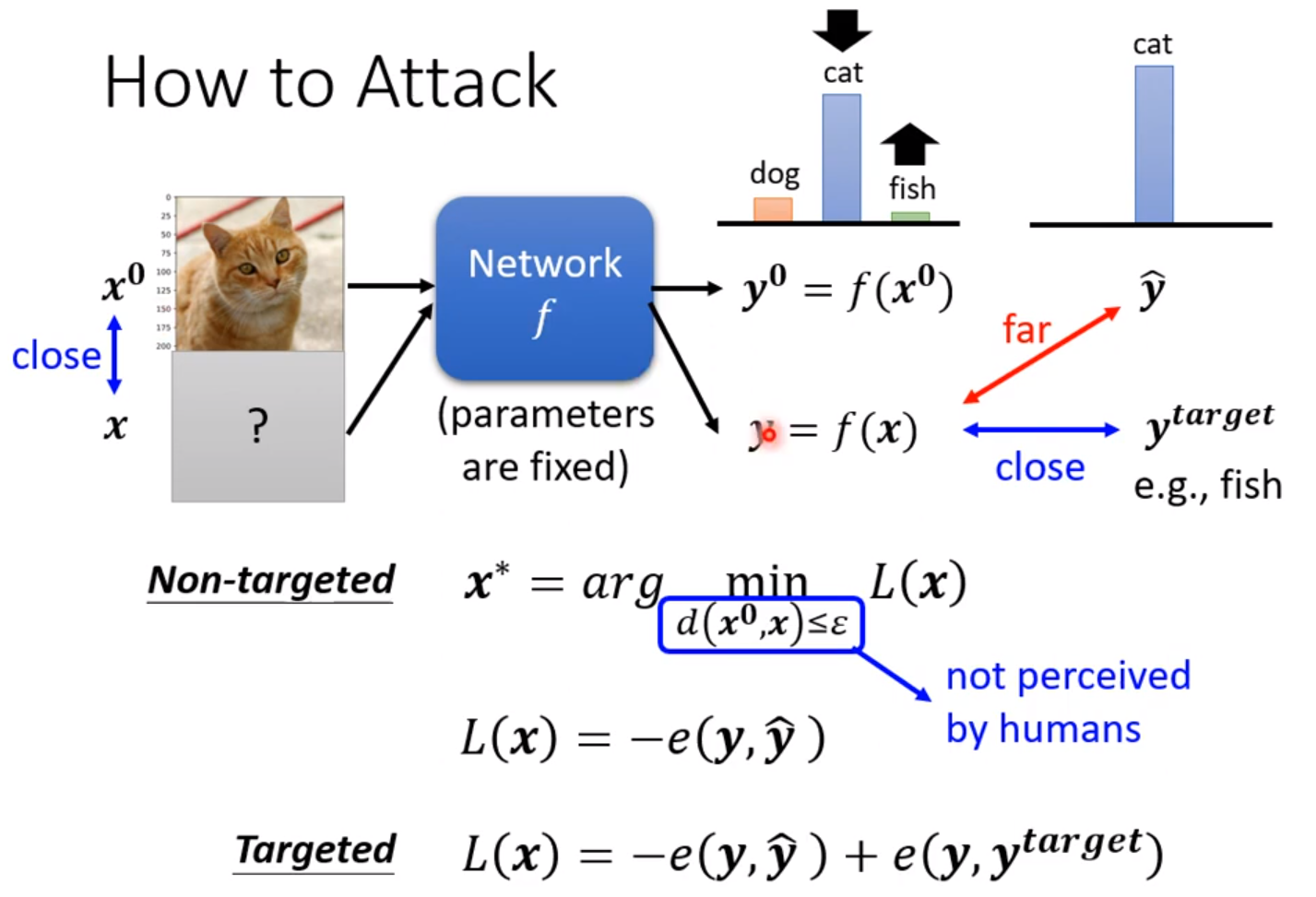

对于图片距离的衡量有多种方式,其中infinity的方式最适合,并且符合人眼观察的习惯。
如果不管输入的图片,那么我们同样是用原来的梯度下降法,只需要将图片像素设定为需要优化的参数即可,把参数初始化为我们需要接近的图片。但是图片要加上一个限制使得图片的距离小于一个人眼能识别的阈值。方法就是当图片的距离大于一个阈值后进行修正。
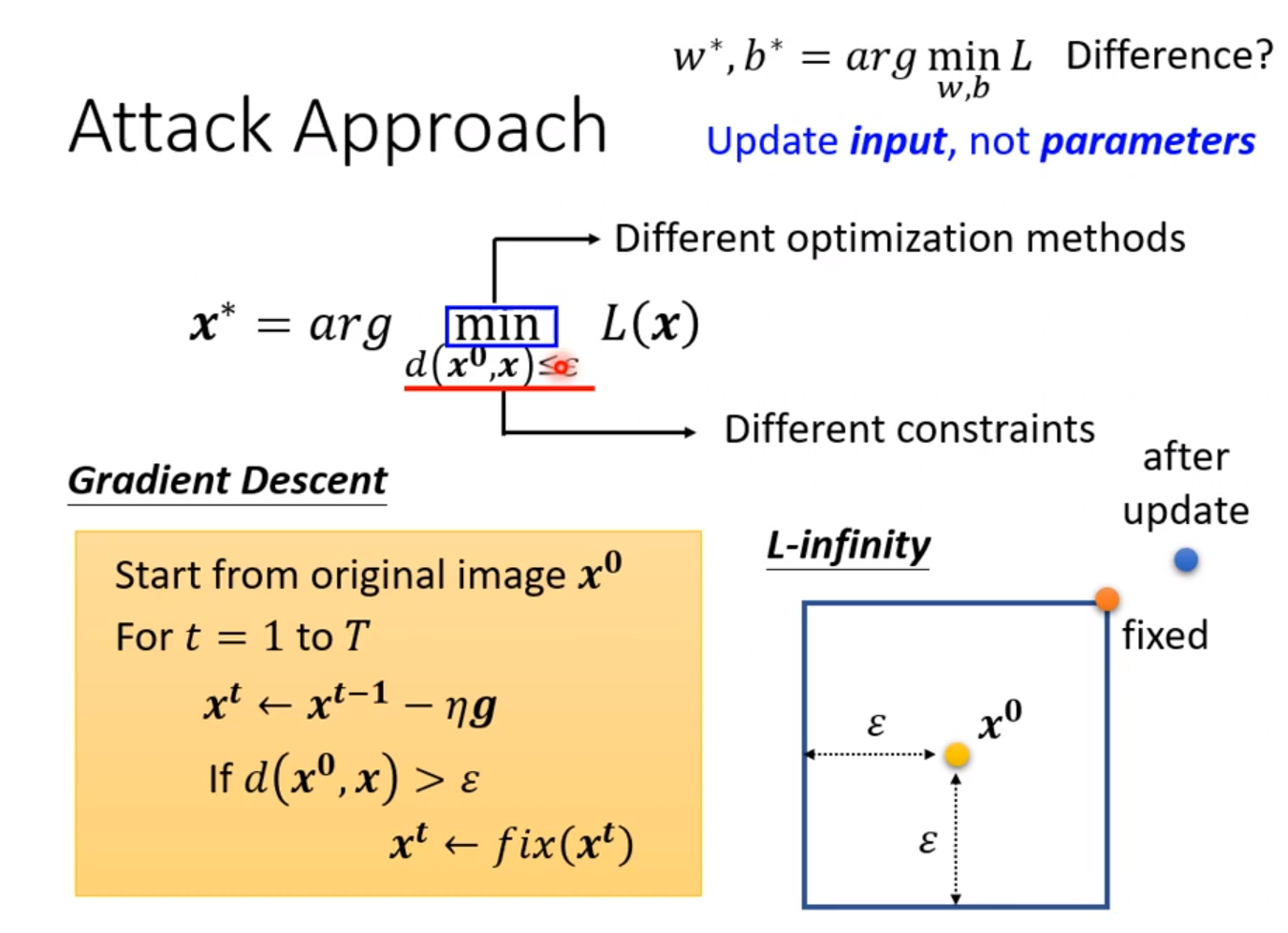
这里有一个只需要update一次参数的方法,往往能一次性达到目的。
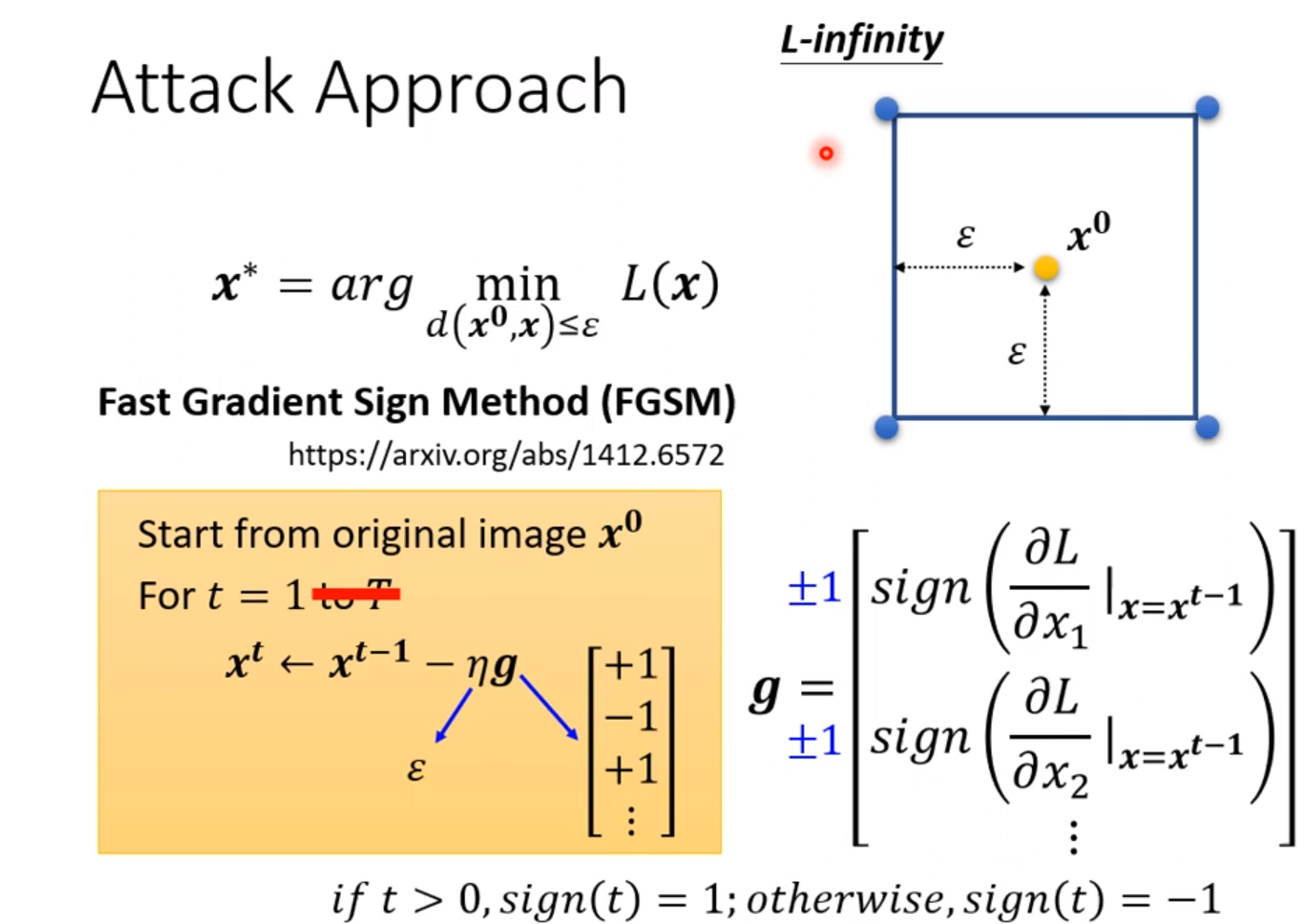
只需要直接往梯度方向直接更新到人眼识别的极限即可,优点是速度大大提升,缺点是与原来的图片偏差较大。
上面的方法的前提是需要知道模型的参数,这种攻击叫做White-Box-Attack。而不知道模型参数的攻击叫做Black-Box-Attack。但是如果我们知道这个Network是用什么训练资料训练的,我们就可以自己训练一个Proxy的Network,这样可能就会和要攻击的对象有一定的相似性。这样如果我们对这个Proxy的Network进行攻击并成功,那么就可以也适用于我们的攻击对象。
但如果我们完全没有训练资料,那么就需要不断测试输入输出,然后把这些成对的资料用来训练自己的模型,那么也有可能训练一个类似的模型。
这种黑箱攻击非常容易成功。

其中的百分比是被攻击对象的识别成果率,其中如果Proxy-Network使用相同的模型相当于White-Box-Attack,一定成功,在Black-Box-Attack的情况下使用其他模型攻击成果的概率也较大。但是这是在Non-Target的情况下,如果指定目标,例如把狗识别成兔子,就比较难。
如果采用Esemble-Attack,将使攻击成果的概率大大增加。
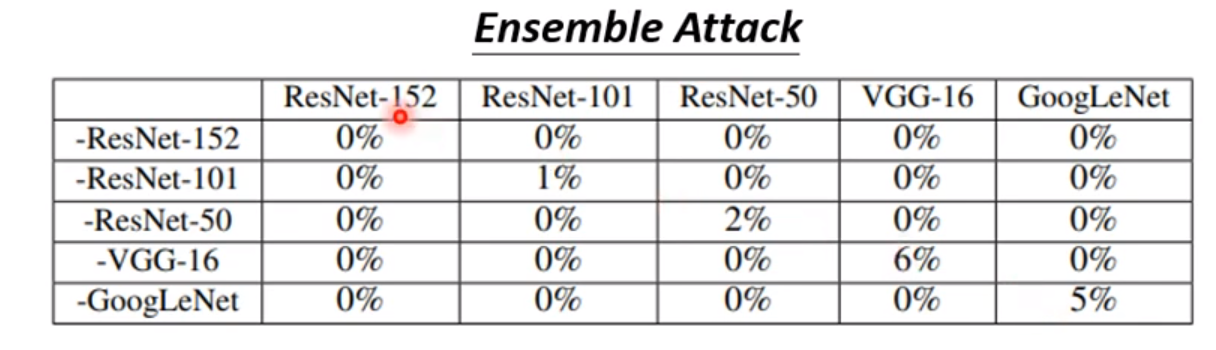
这种方法是同时训练多个种类的Network,使得我们的攻击数据在每个Network上都成功,图中左边的数据前面的减号是指用除了这种模型以外的几个模型训练成功。所以对角线才是Black-Box-Attack,其他的地方是White-Box-Attack。所以结论是如果我们的数据在多个模型上的攻击都成功了,那么在我们的目标模型上的攻击也很大概率是成功的。
下面是原因:

其中的蓝色区域是模型成功辨识的区域,我们发现不同模型都有一定的相似程度,在一个方向上的辨识范围特别窄,我们稍微动一下这个维度,那么就会导致模型识别失败,而这个维度在所有模型上的识别范围都是类似的。
这种观点把成功的原因归功于data而不是model。模型之所以会产生误判是因为资料本身的特征,所以模型们都会学习到这种特征而产生误判。当有足够的资料,就有可能避免这种攻击。不过这是部分人的观点,没有得到公认。
这些攻击不仅运用在图片上,也可以运用在文字和语音上。

以上的攻击是基于数位的世界,我们需要在机器获取数据后对数据进行处理才能骗过机器,如果现实时间中我们没有办法对既定的图片或数据进行修改,那么有没有可以化个妆就把系统欺骗过去呢?这是有可能的。不过化妆是一种不稳定的修改,有人发现了一种通过戴特殊眼镜的方法。

也有人对车牌辨识系统进行攻击:

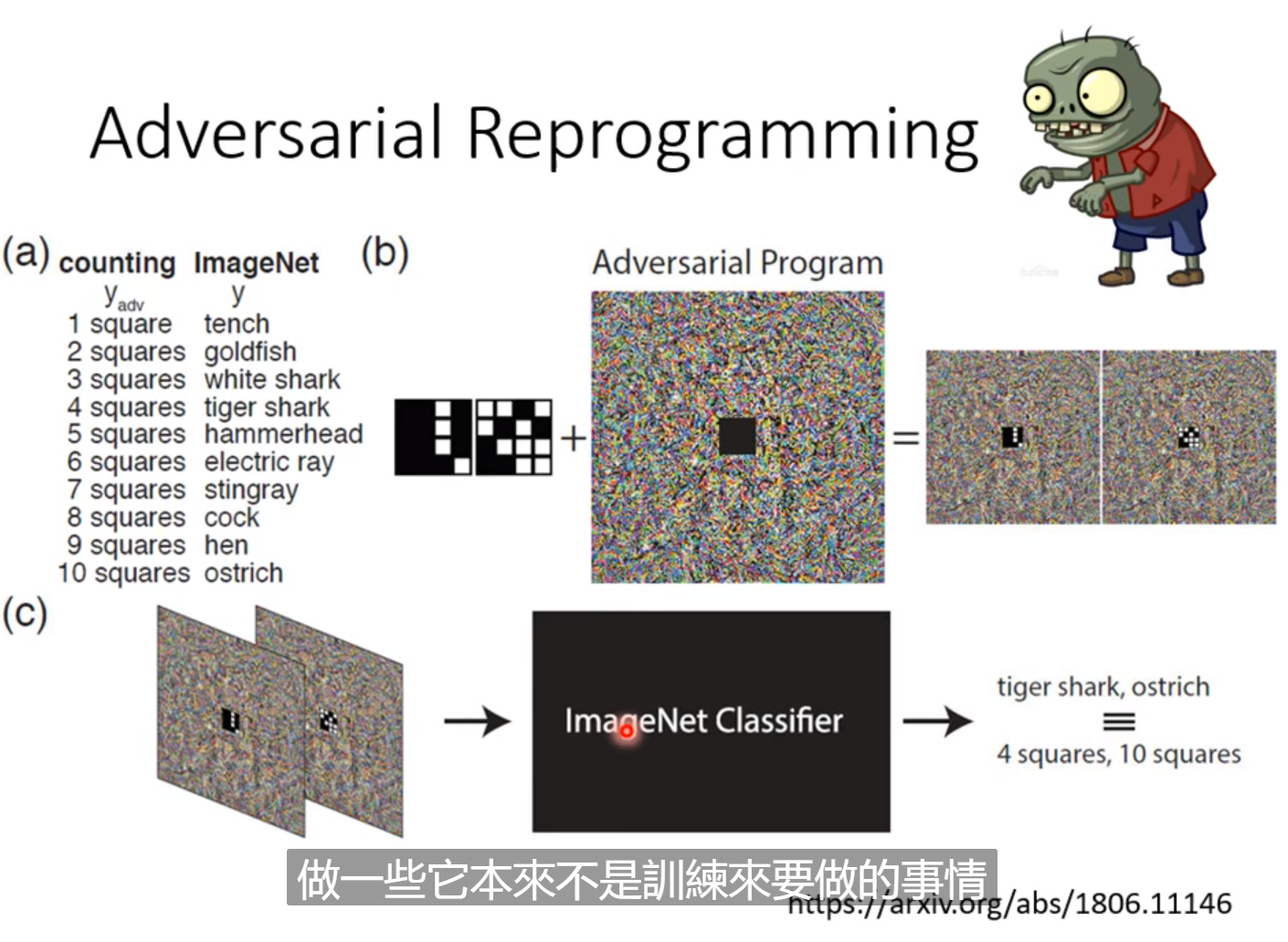
还有一种攻击方式是Adversarial-Reprogramming。论文中做了一个方块辨识系统数图中有几个方块。但不训练自己的模型,可以寄生在一个已有的模型上面。当输入的图片中检测出几个方块时,就使模型输出对应一定的结果,这样就能操控别的模型做本来不是训练要做的事情。只需要把图片嵌入一堆杂讯的中间,就能时原本的模型按自己的要求进行输出。
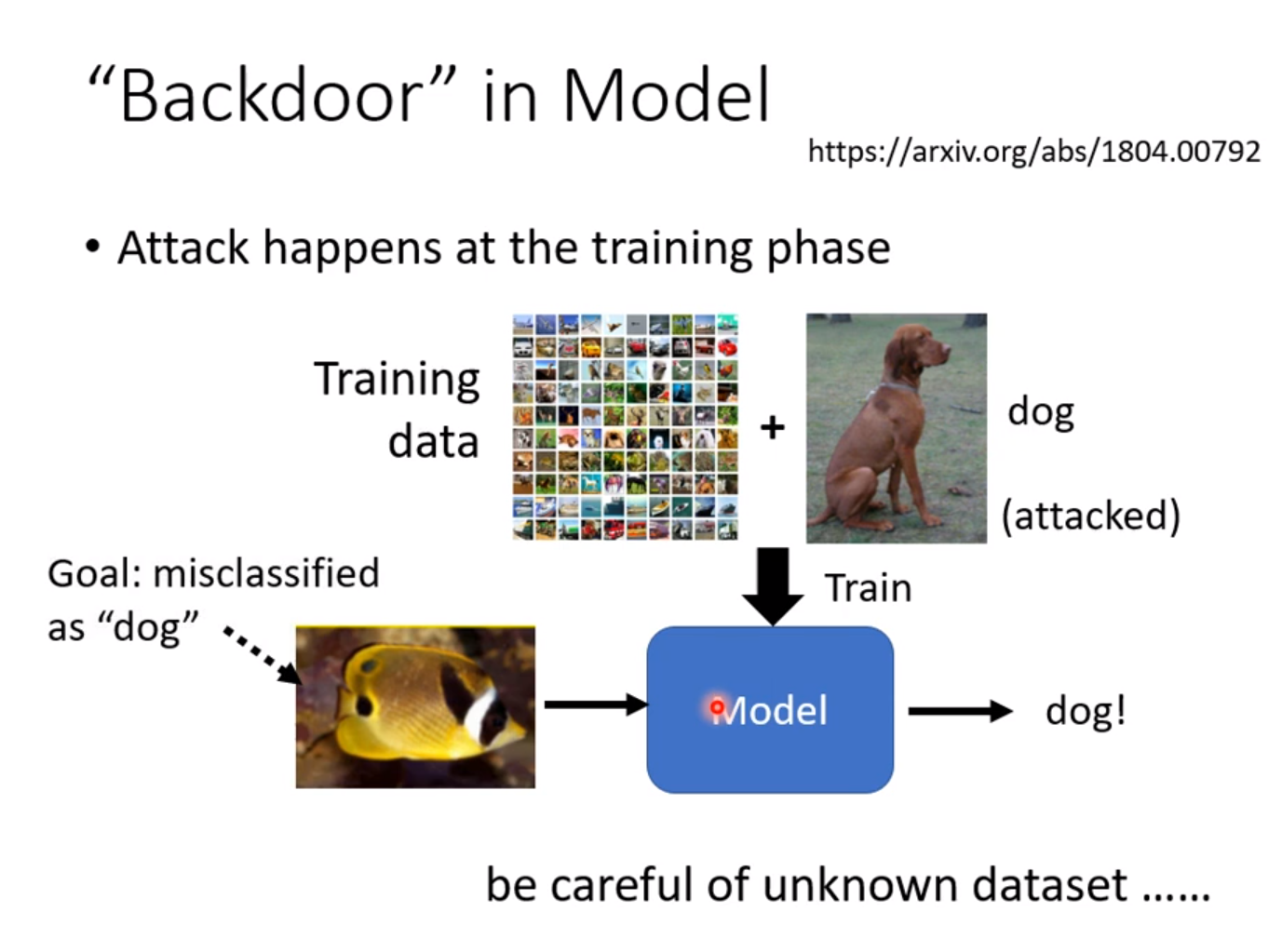
还有一种攻击是从训练阶段就展开攻击,在一堆正常的训练资料中事先加入我们精心设定的图片,看起来没什么问题,但是机器训练完成后,就会对特定的一个事物产生误判,但是也有一定限制。
防御方式
防御方式分为被动防御和主动防御。
Passive-Defense
被动防御的方式是模型训练好之后不再更改,而是在数据中加入一个Filter(过滤器)。普通的数据经过过滤器后不受影响,但攻击数据经过过滤器后会大大削减威力,让你的Network不会辨识错误。一个最简单的方法是把图片稍微模糊化,这就可以做到很好的防御效果了。缺点是模糊化后造成的副作用是加强了识别的不确定性,可能会导致正常的图片辨识错误,所以模糊不能过头。第二种方式是把图片做某种会造成失真的压缩,然后解压缩,失真本身就能使攻击图片失去威力。第三种方式是图片用Generator重新生成。


被动防御有很大缺陷,如果别人知道你使用了某种防御方式,例如模糊化,那么相当于在网络前加上一层。别人也把这一层加入攻击过程中,产生的数据也可以骗过我们的模型。
一种方法是我们自己都不知道自己用什么方式来过滤。一种具有随机性的方式可以在一定程度上解决这个问题:
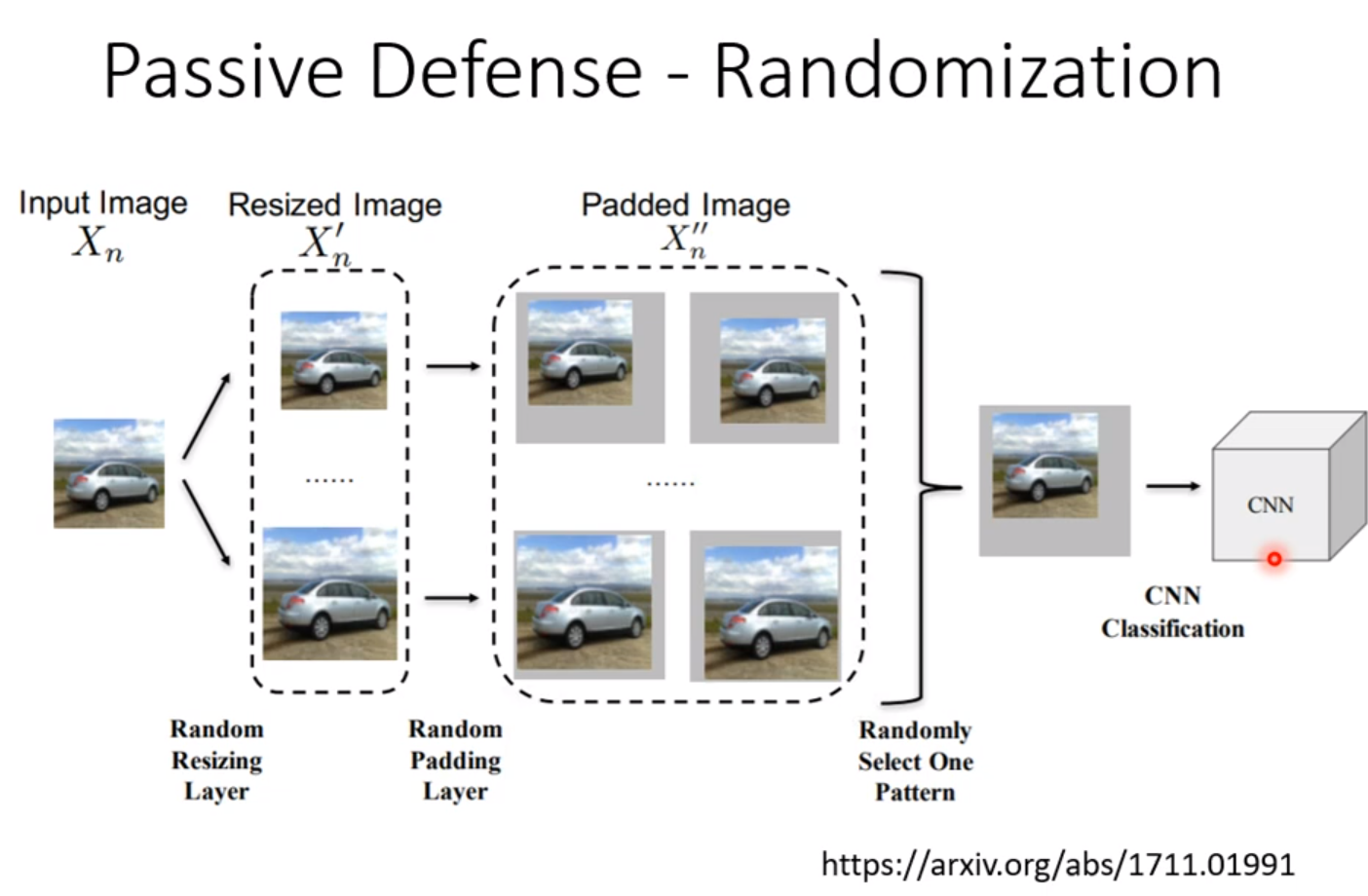
但如果别人知道你的随机分布,也是有可能攻破这种方式的。方式是用Univeral-Attack。
Proactive-Defense
首先,我们用正常的资料对模型进行训练,训练完成后,我们自己对模型进行攻击。但我们把具有攻击性的图片都标上正确的label。这样训练出来的model就有办法识别具有攻击性的图片。这第二次训练完成后再重复进行攻击,如此反复。这其实是一种Data-Augmentation的方式,因此有人把Adversarial-Training当成单纯的资料增强的方式。就算没有人攻击你的模型,也可以用这种方法产生更多的资料,避免overfitting。
这种防御的方法也是有可能被攻破的,我们必须实现考虑到别人采用的攻击方式,如果我们在训练的时候没有考虑到别人的攻击算法,别人用了新的方式进行攻击,往往就能成功。并且需要大量的运算资源,很花时间。有一种方式是Adersarial-Training-for-free不用占用太多的运算资源,这里不细讲,文献链接在图片中。




