Self-supervised-learning
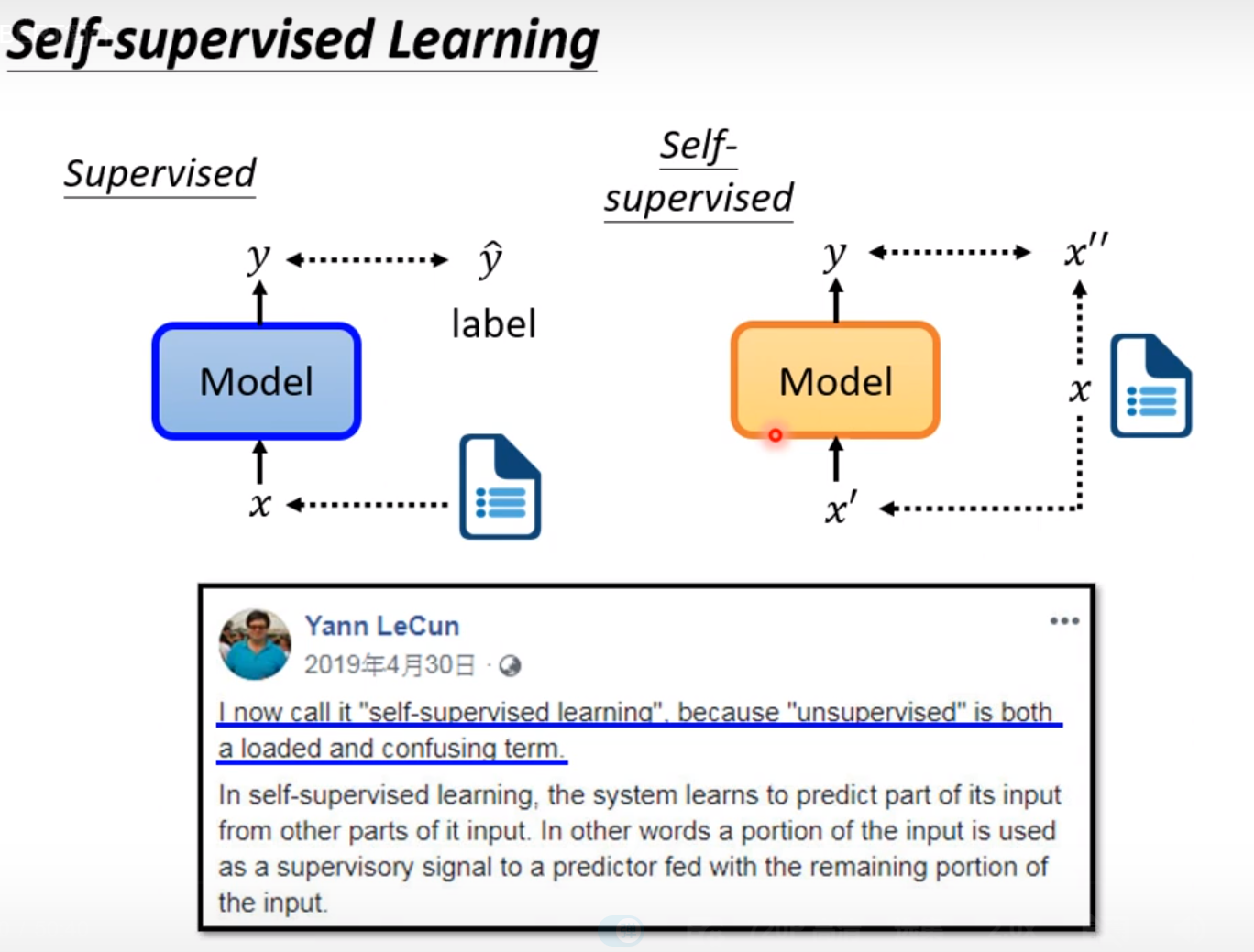
在《李宏毅机器学习2021》中前面讲解的方法都是监督式的学习。给定数据和标签,这样才能训练supervised的model。
而self-supervised是在自己没有label的情况下想办法做supervised。
方法是把没有标注的资料分成两部分,一部分作为模型的输入,一部分作为模型的标注。然后让模型的输出跟模型的标注越接近越好。
下面用BERT来举例:
Transformer的Encoder就是BERT的架构。这就意味着输入和输出的序列长度一样。这种结构一般用于自然语言处理。
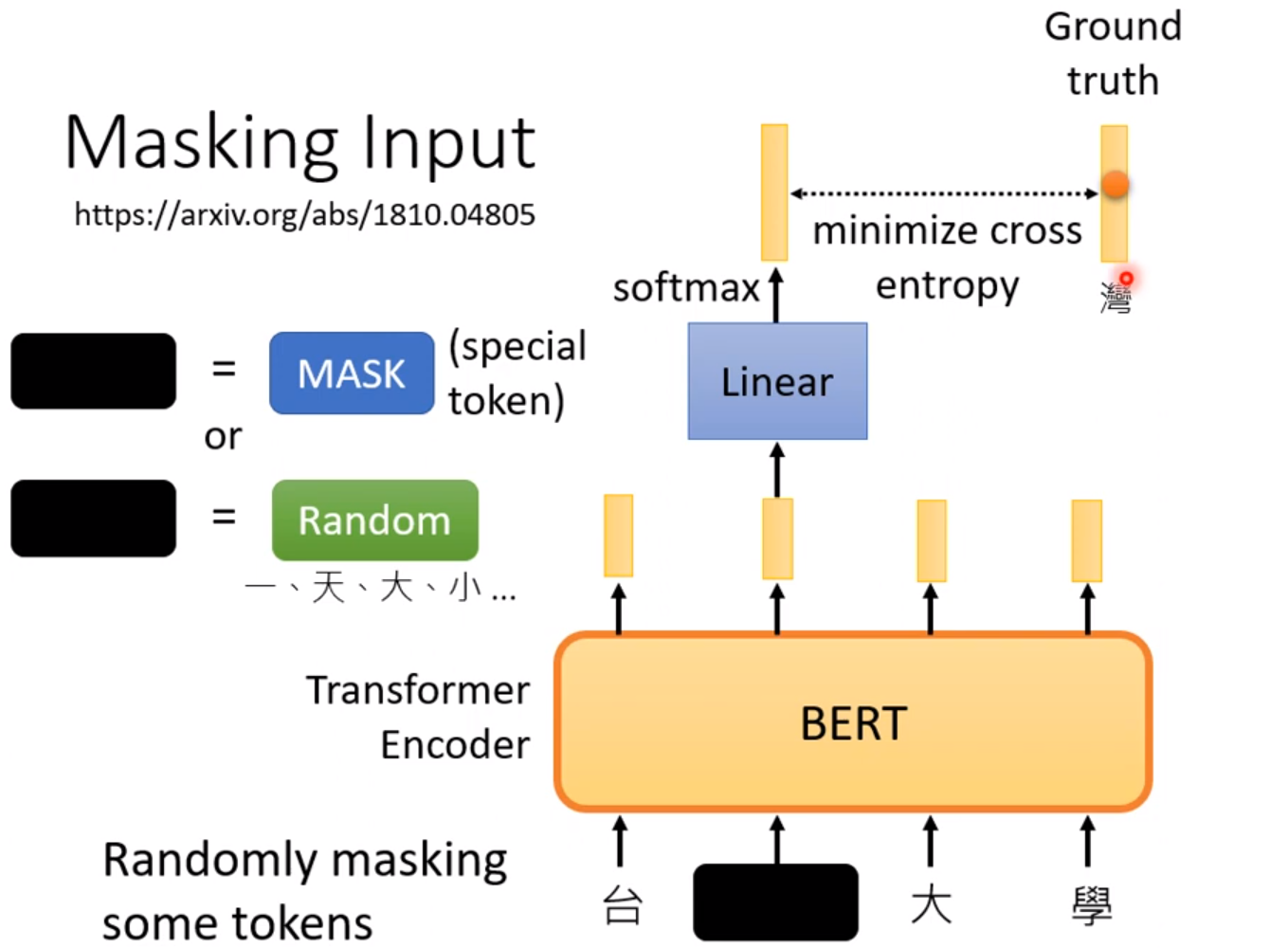
把 一句话的某些字盖起来,用其他的符号代替,我们尽量输出原本那句话。这就是Masking。除了填空这种任务外,对BERT进行调整后可以适用于各种各样的任务,这叫做Fine-tune。
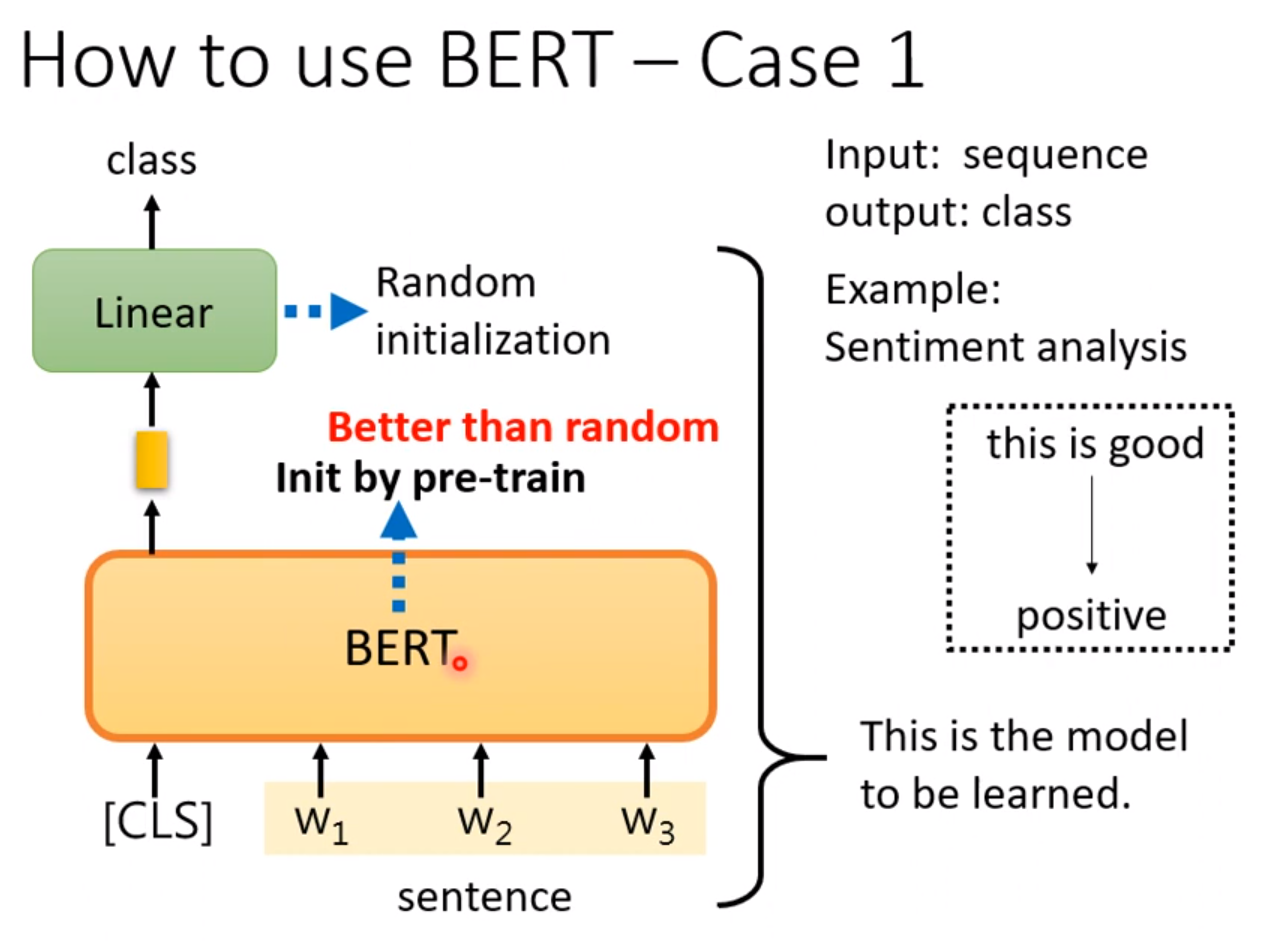
其中Linear的参数才做随机的初始化,BERT的参数是做填空题的参数直接拿过来进行初始化。这就是pre-train。这样得到的结果往往比随机初始化好。接下来的例子类似:

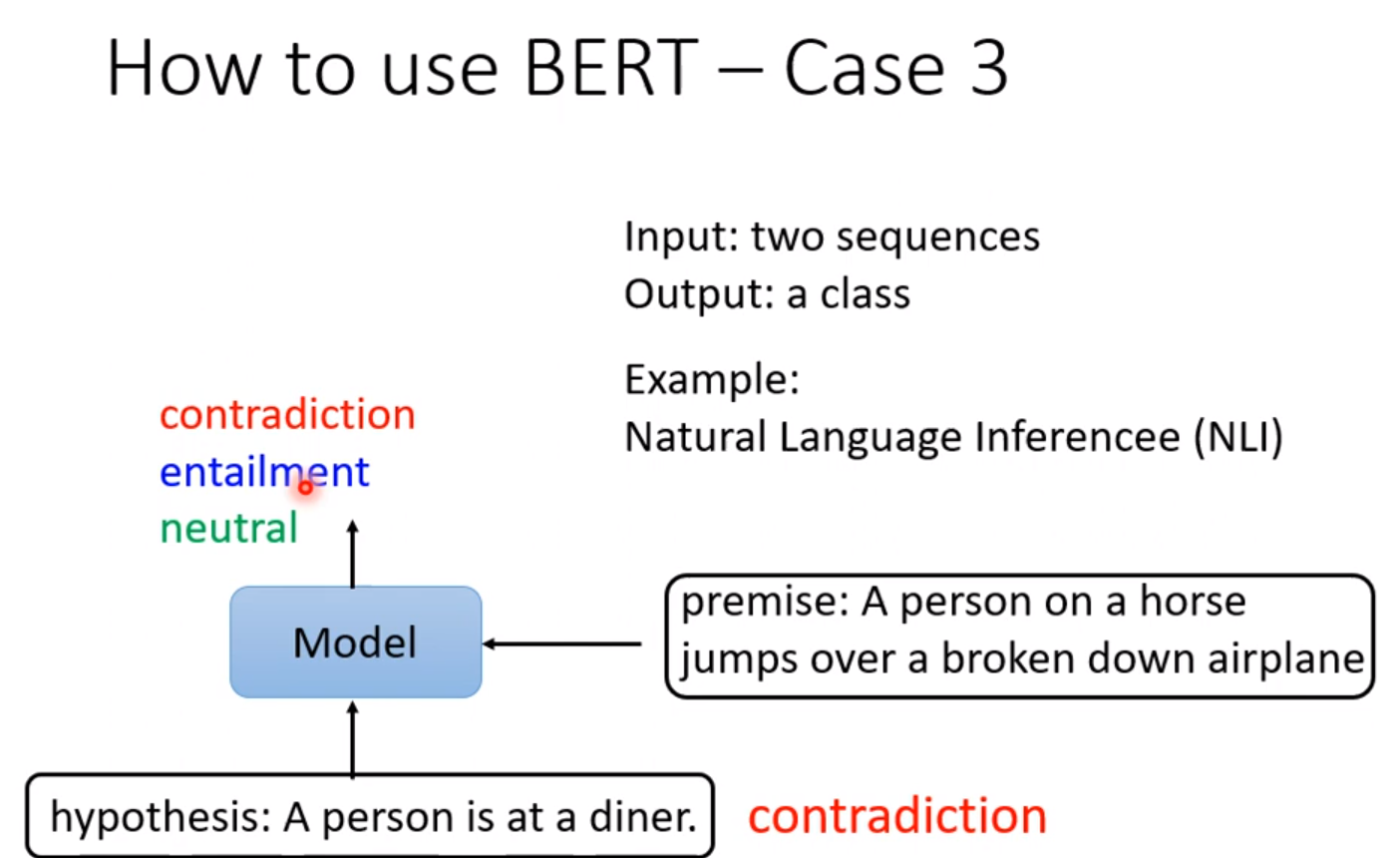
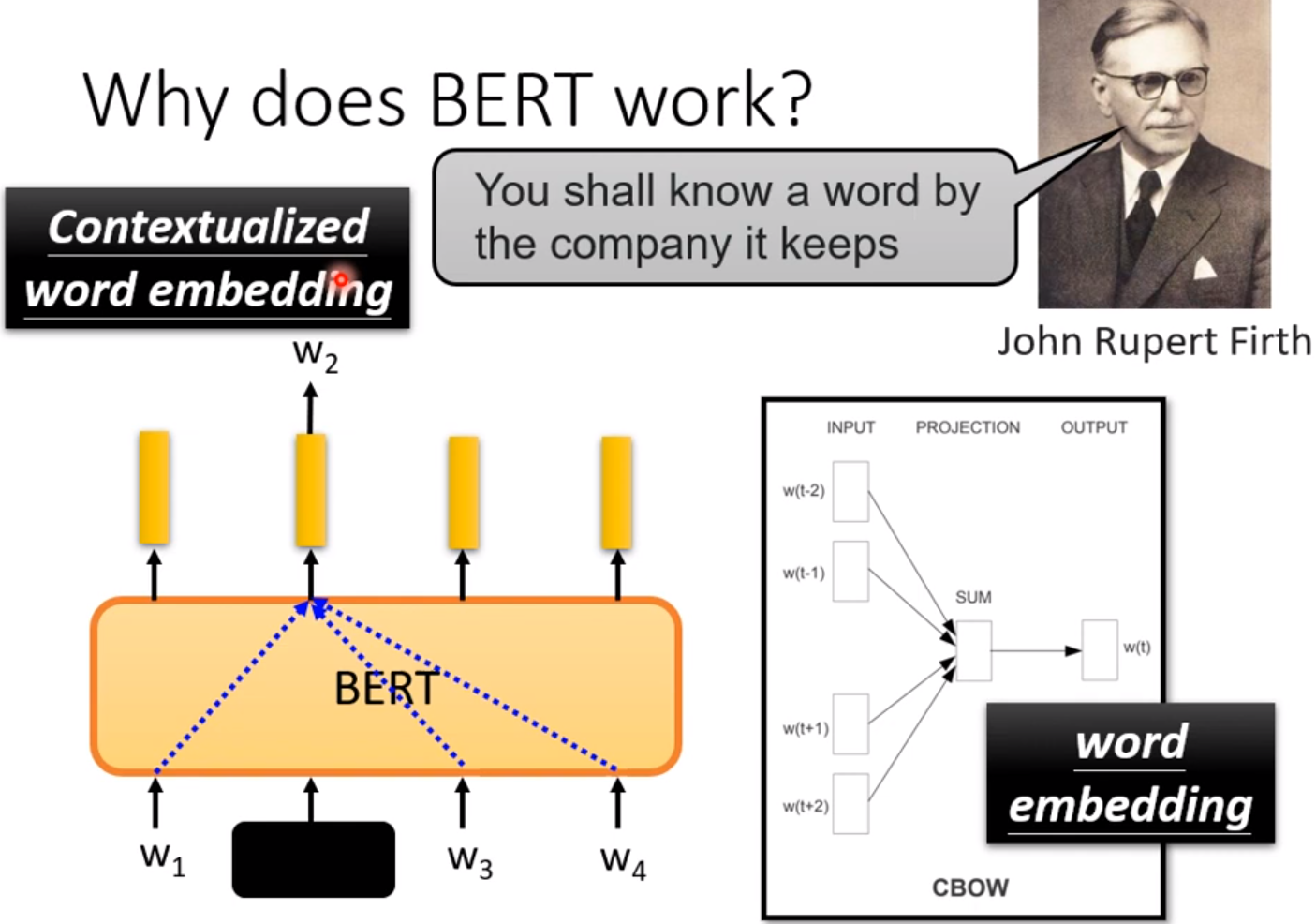
那么为什么BERT的pre-train有用:
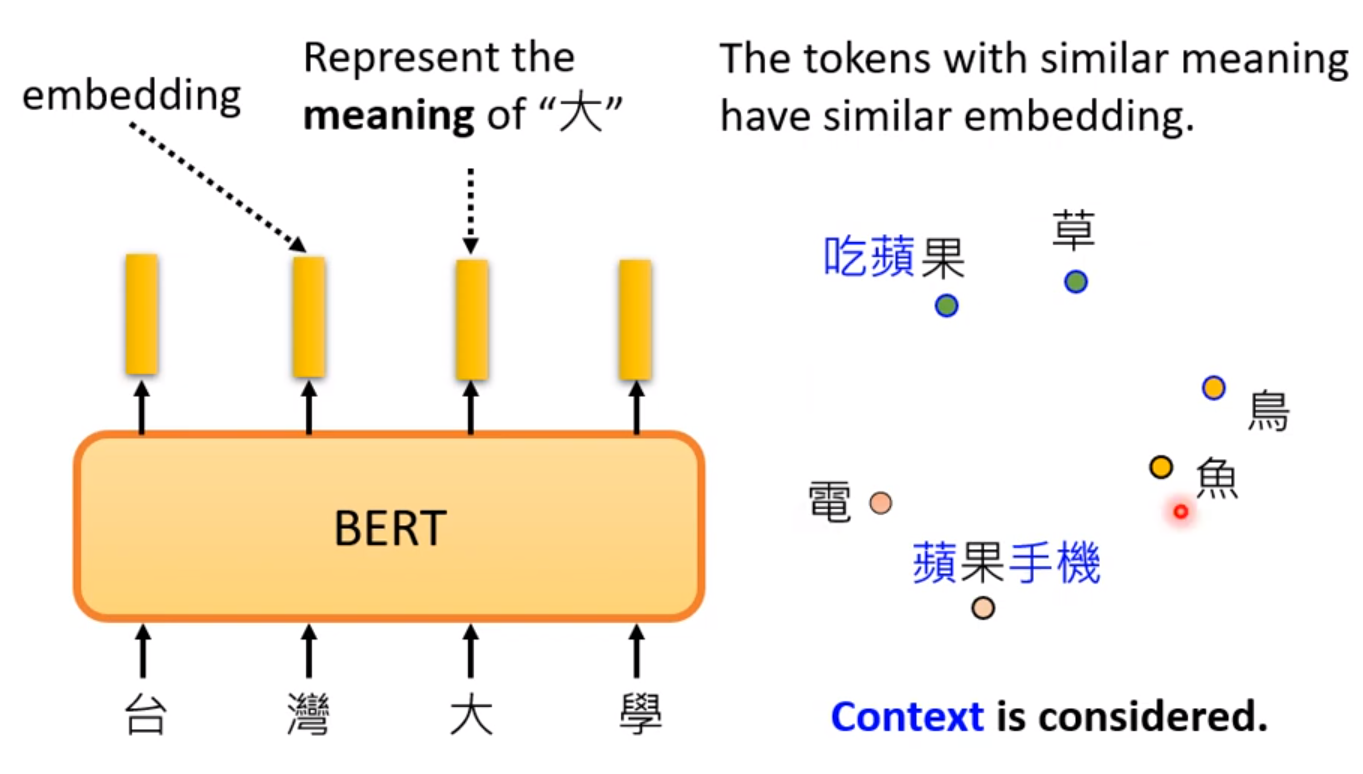
这意味着训练过程中BERT已经可以了解句子中每个字的含义。这是基于上下文的训练得出的经验。
然后简单说一下GPT系列的模型:
这个系列模型的任务是预测接下来的Token:
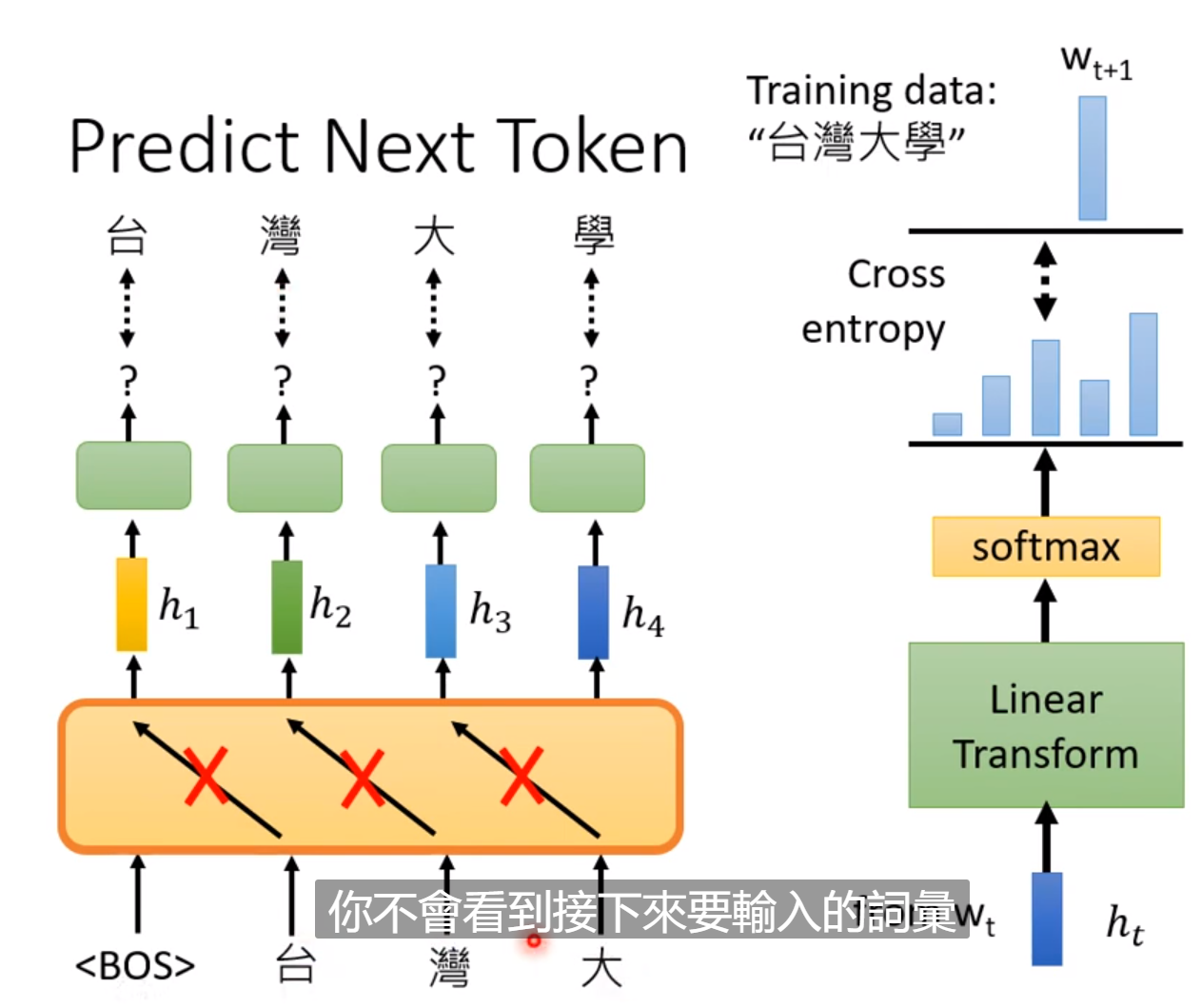
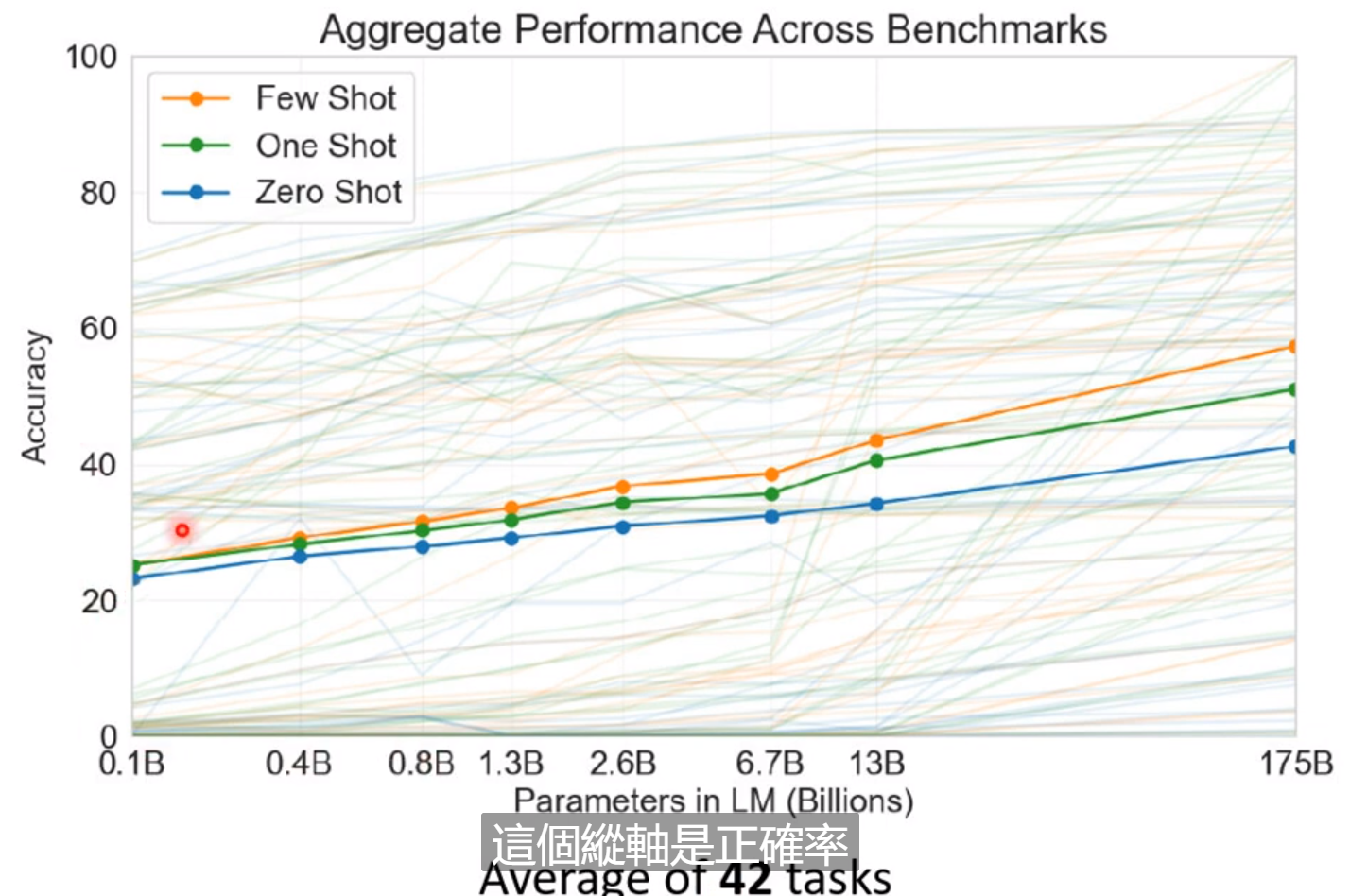
这样不断预测下一个token可以产生完整的文章。

还有进行翻译的功能。
Auto-encoder
不用标注资料的学习叫做self-supervised-Learning。例如做填空。而且训练完后能够用到下游的任务中。还有一种古老的不需要标注资料的任务叫做Auto-encoder。因此也可以视作Self-supervised-learning的一部分。

这种把高维度转换成低维度的东西叫做dimension reduction。能够做这种变化的原因是因为特定类型的图片是有规律的,只有能小一部分的图片符合这个规律,因此我们可以通过模型降维,来提取出这个规律。然后就可以再通过一个模型进行还原。这个降维的好处是把复杂的向量用简单的方法来表示。这样我们只需要比较少的训练资料就可以让模型完成训练。这就是Auto-Encoder的概念。
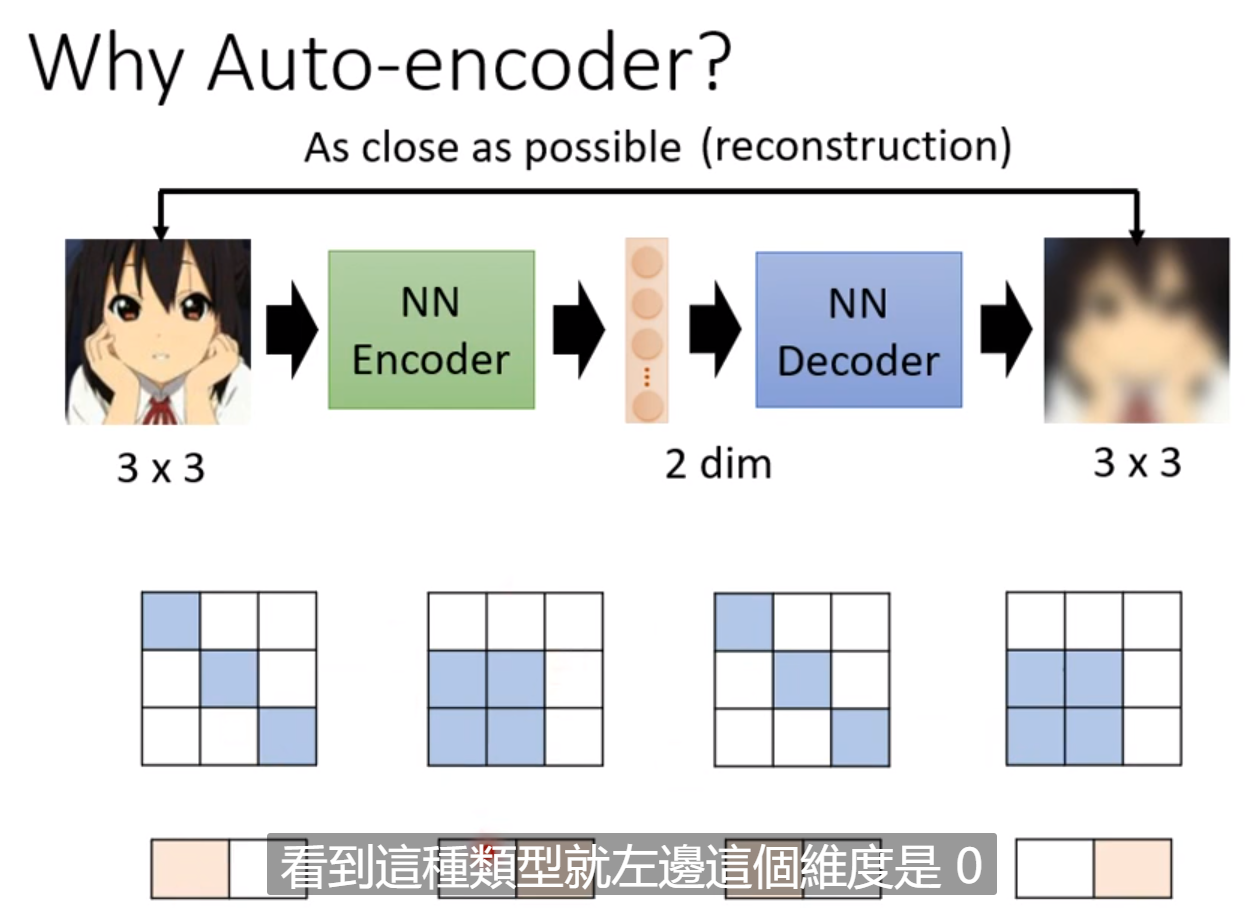
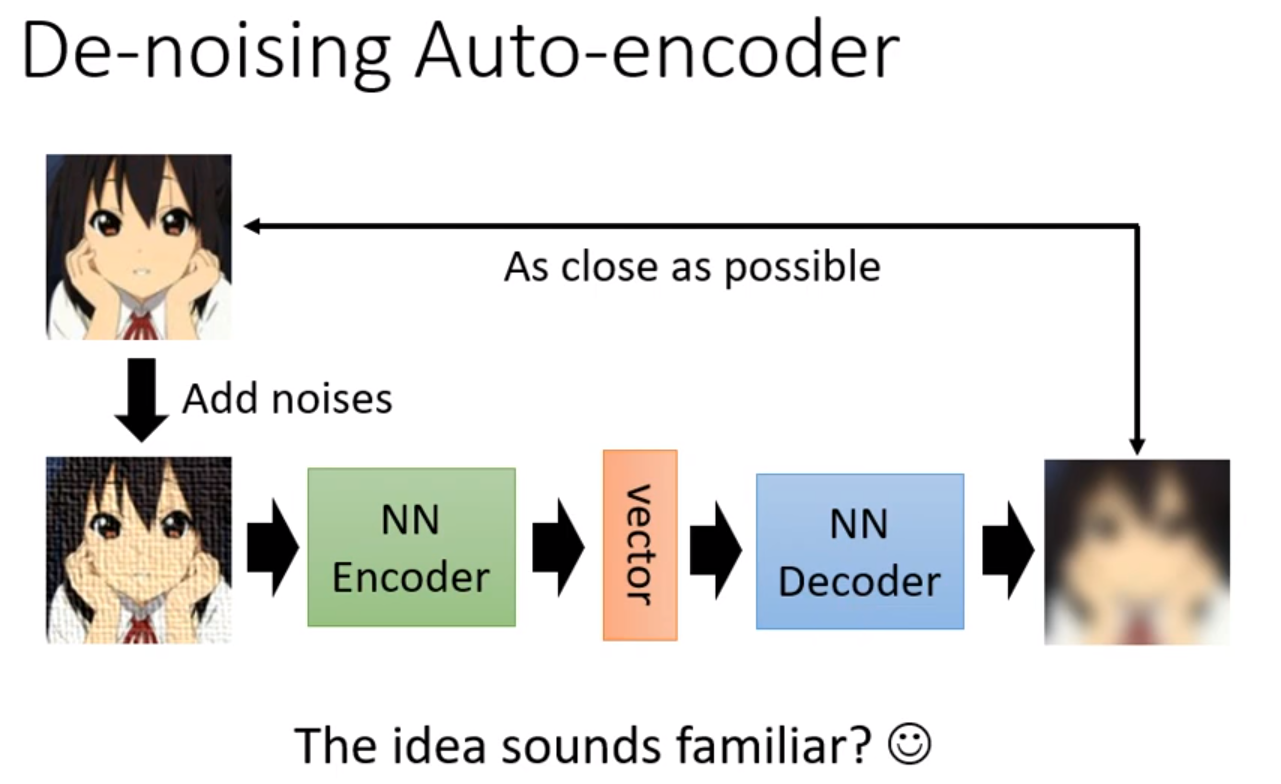
这种方法不仅能从高维向量中提取数据,还能够去除噪声。
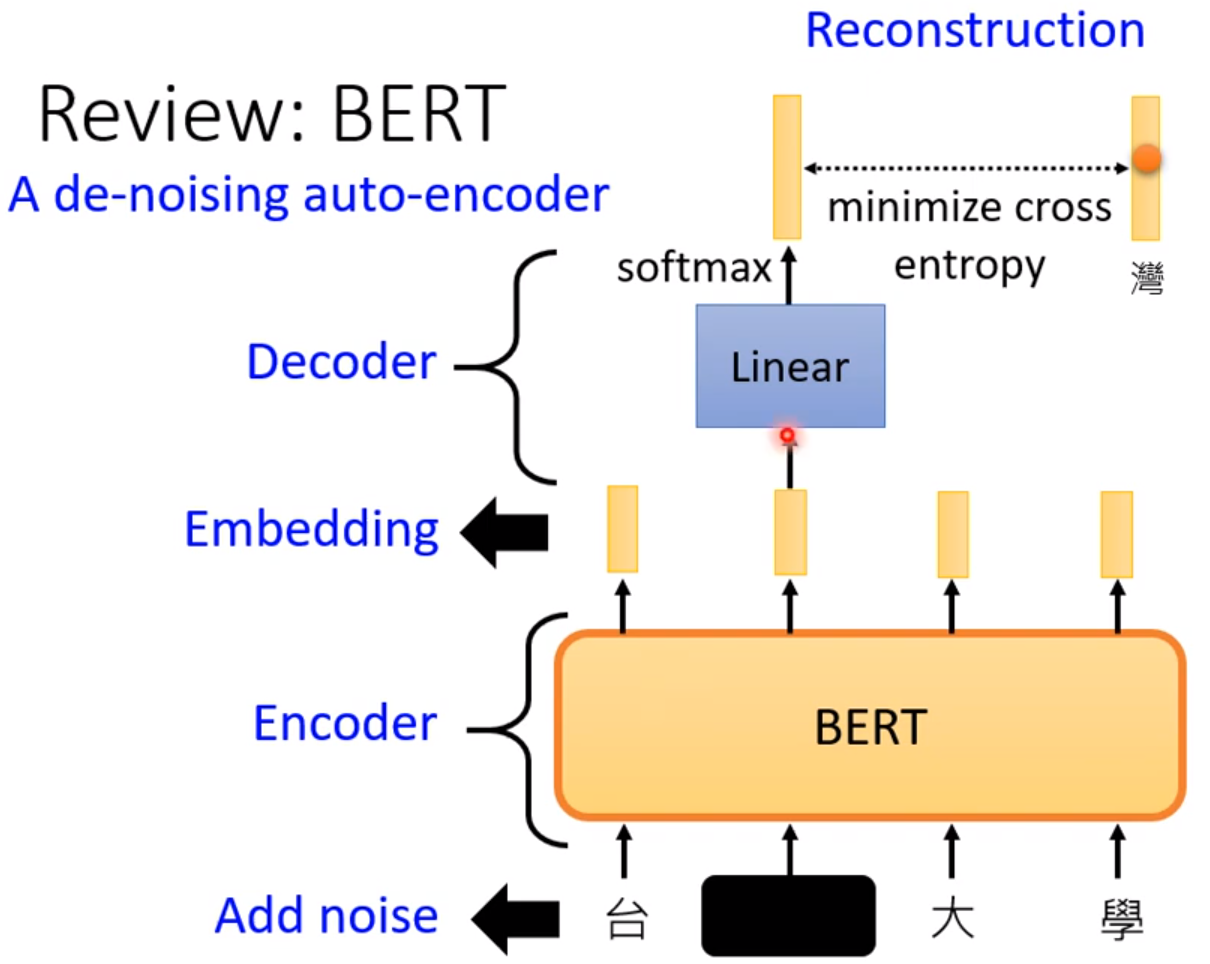
因此BERT是一个De-Noising的Auto-Encoder。
Feature Disentangle
上面的Auto-encoder虽然对数据进行了降维,但是我们无法得知降维后的向量的哪一部分代表了什么信息。为了使数据可以分开成一组组代表特定特征的向量,我们就有了Feature-Disentangle的技术。
这种计算的应用是Voice-Conversion语者转换。可以将一个人的声音转换为另一个人的声音,甚至同时转换语言。做法是在提取出表示声音信号的向量后,分解为表示内容和声音特征的两部分。这样把一个人的内容部分和另一个人的声音特征部分进行拼接,就能用一个人的声音讲另一个人的内容。
Discrete Latent Representation
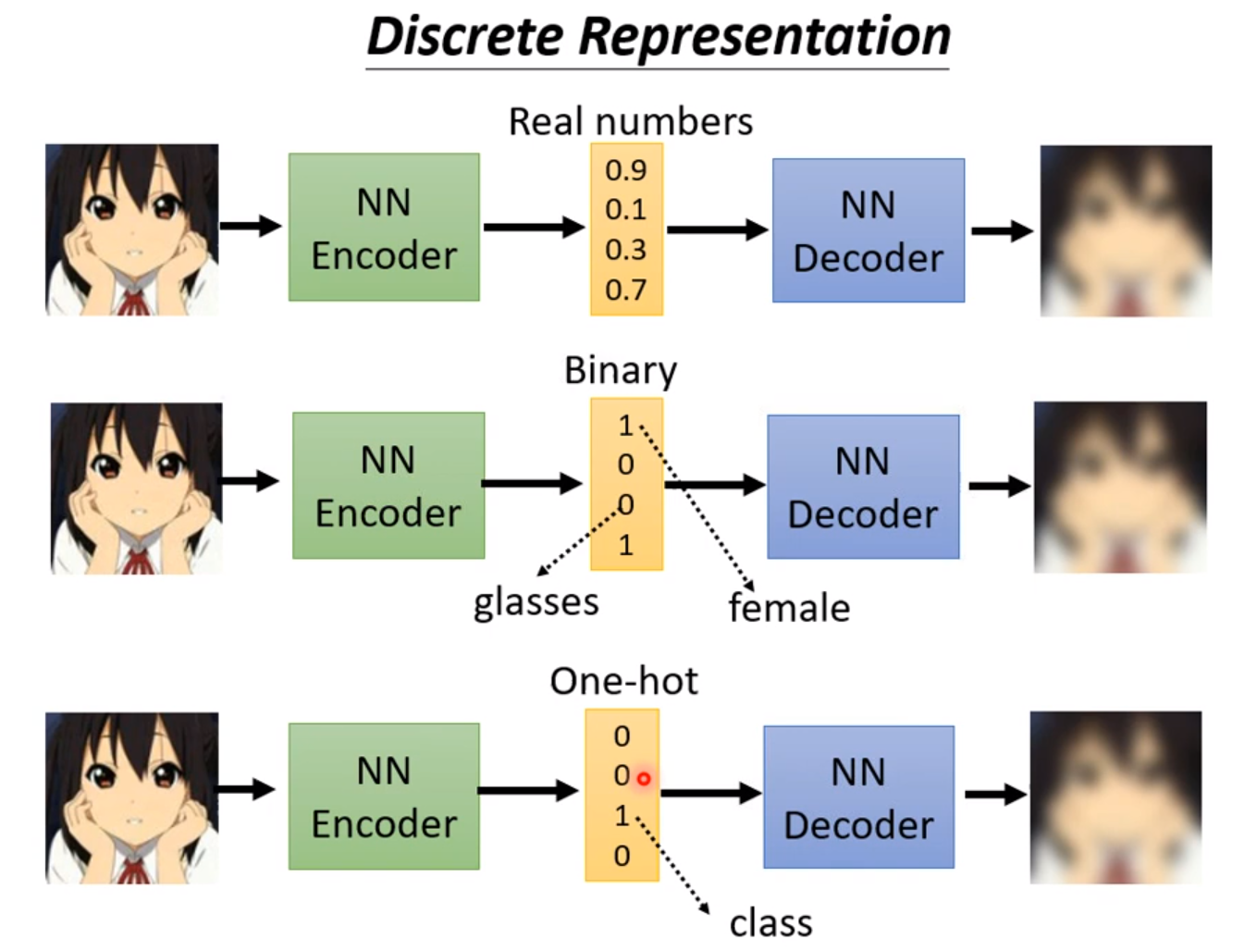
如果强制使得提取出来的向量是二进制的(Binary),甚至是One-hot的,我们就可以十分简单的表示有还是没有这个概念。例如有没有眼睛,男生还是女生。解释输出更为容易。甚至可以做unsupervised-learning。例如手写数字不用给标签,然后使其提取一个十维的one-hot向量,那么每一维就可能对应到一个数字。
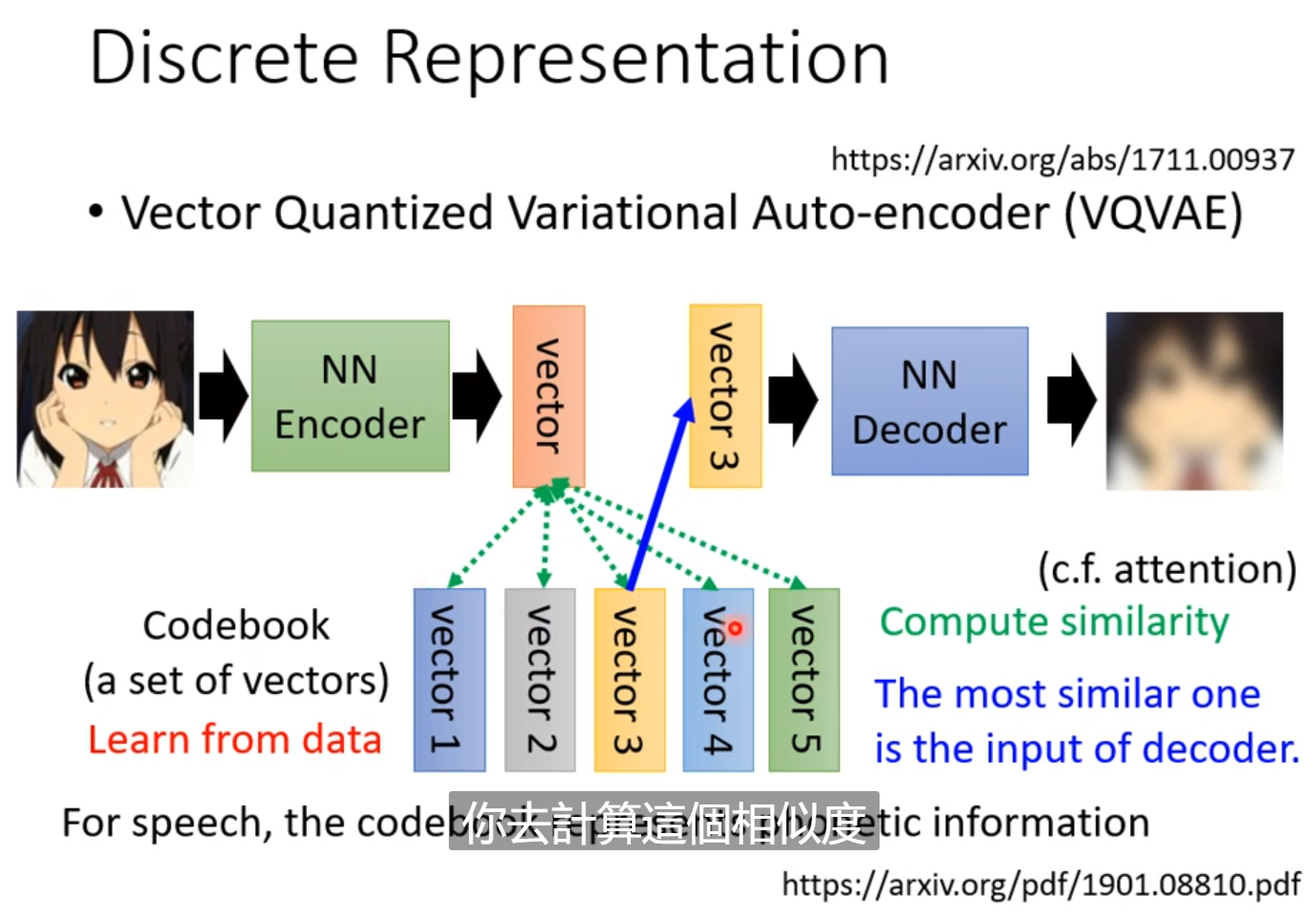
这个Codebook也是资料中学习的,计算相似度,然后用Codebook中相似度最高的向量来生成图片,和原来越接近越好。好处是降维后的向量只有有限种可能。如果输入是语音,那么可以学到最基本的发音单位。
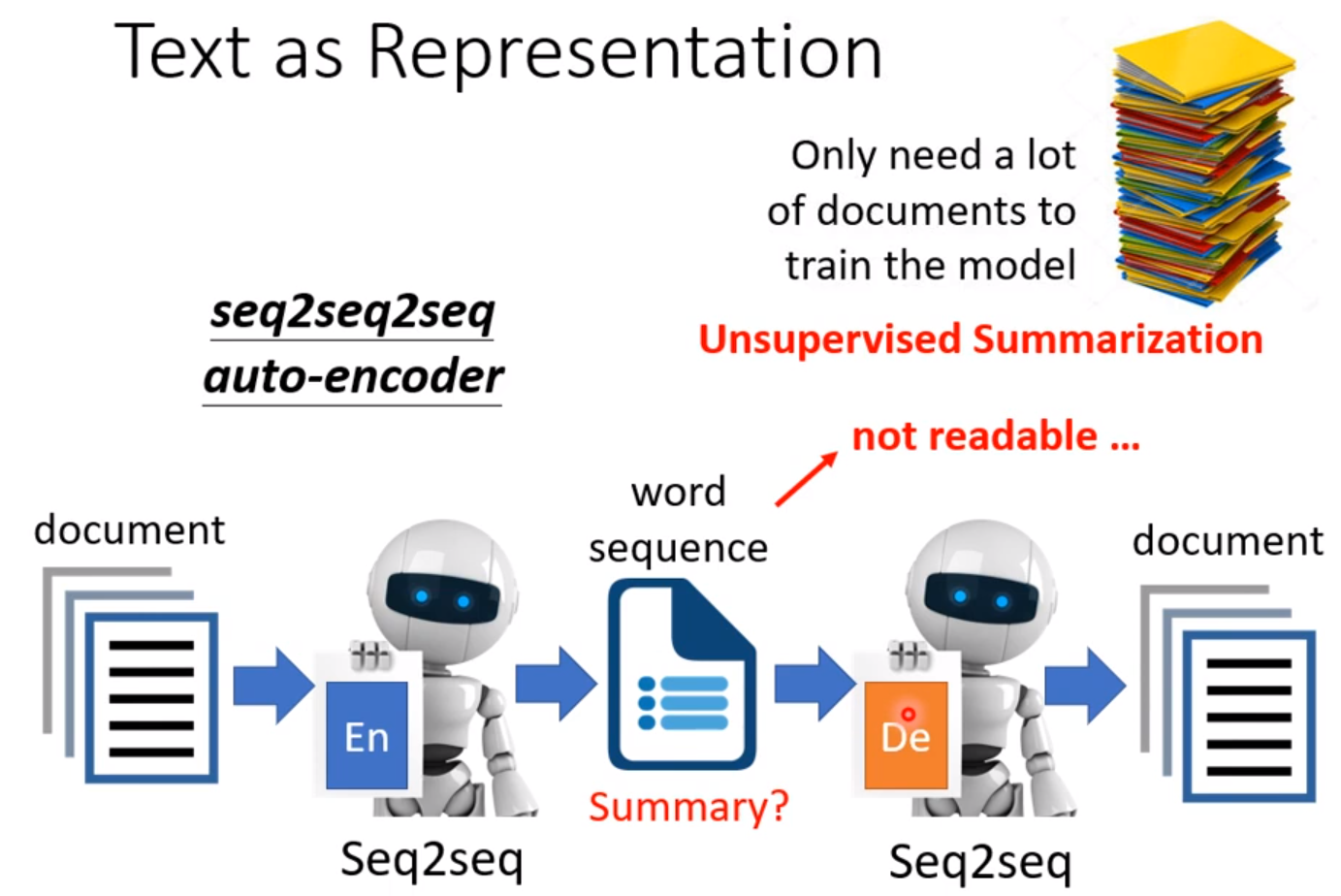
如果不用向量做Embedding,而是一串文字也可以。好处是输入一篇文章,降维成一串文字,如果这串文章能还原文章,这串文字可以是文章的摘要。但通常产生的不是摘要,而是人看不懂的文字,但能还原文章。
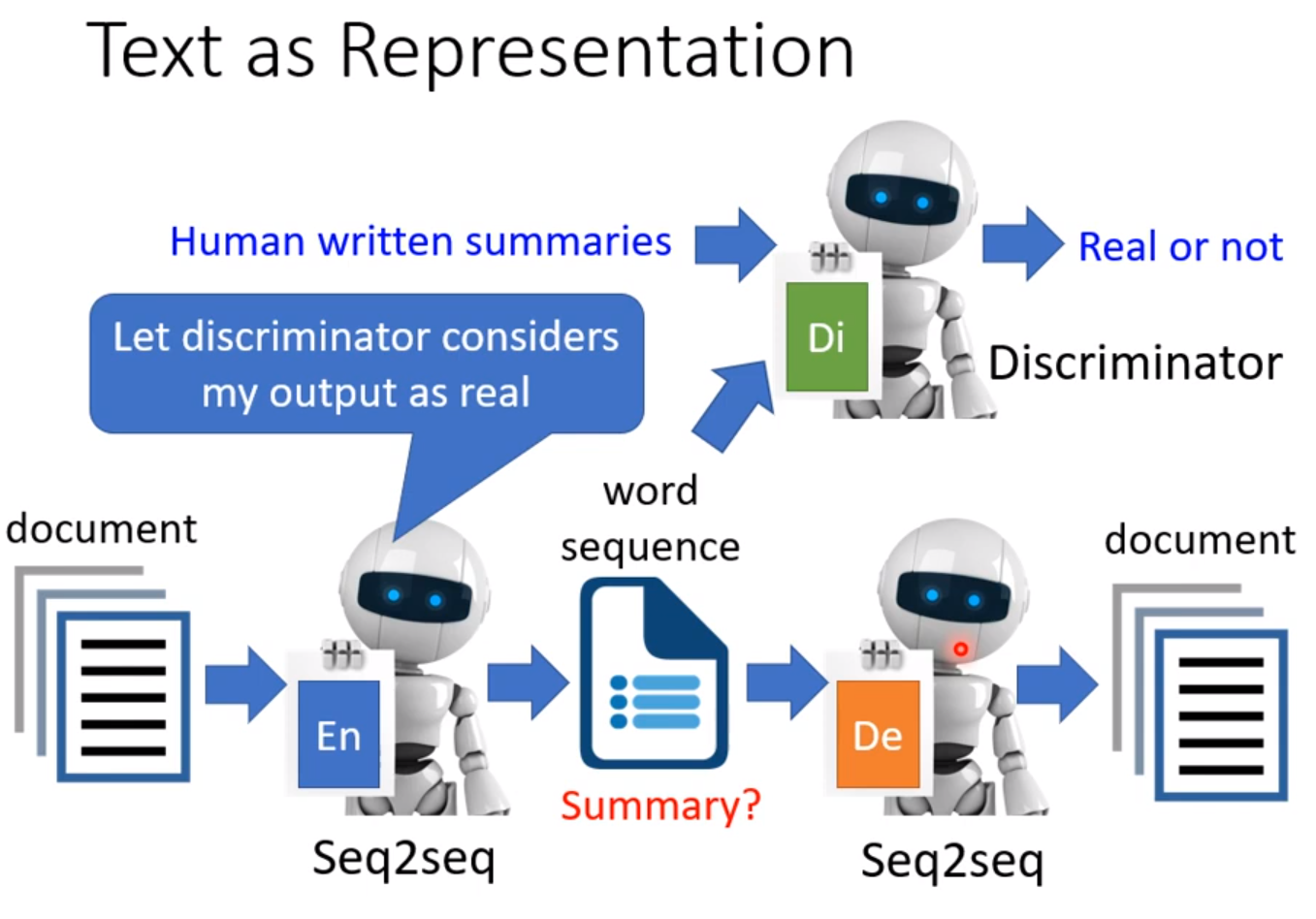
解决办法是用GAN,把人写的摘要和机器的摘要输入给Discriminator来识别。由于输出是一段文字,接给Discriminator和Decoder的方法是用RL硬做。没办法train的问题都用RL硬做。
我们刚刚用的都是Encoder,如果把Decoder单独拿出来,就是一个Generator。当图片太大的时候,一个压缩方法是把Encoder的输出当做压缩的结果,而Decoder就是解压缩。缺点是可能会失真。
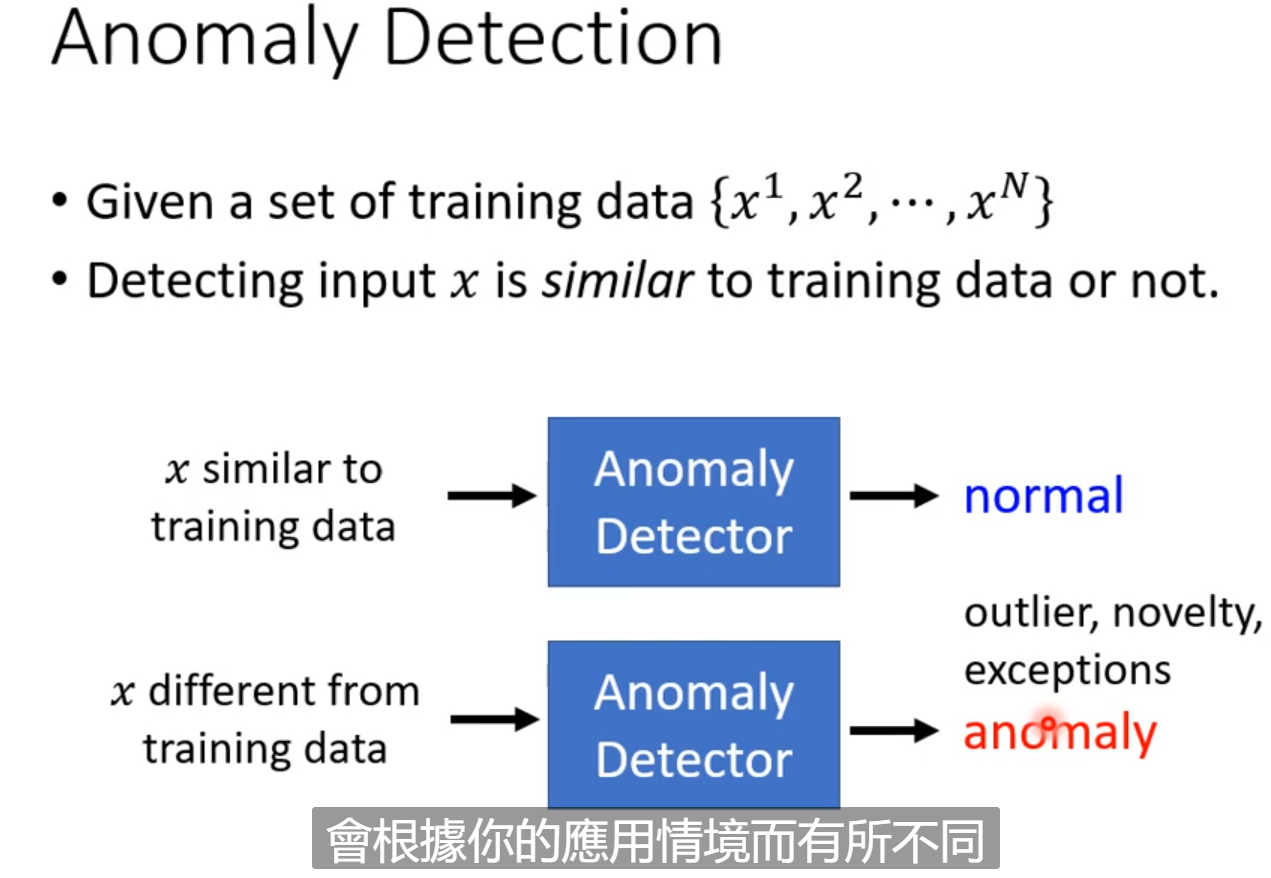
这里一个技术是Anomaly Detection(异常检测)。就是每进来一笔新的资料,检测与之前的资料相不相似。前提是我们必须收集到一大堆正常的资料而没有异常的资料。
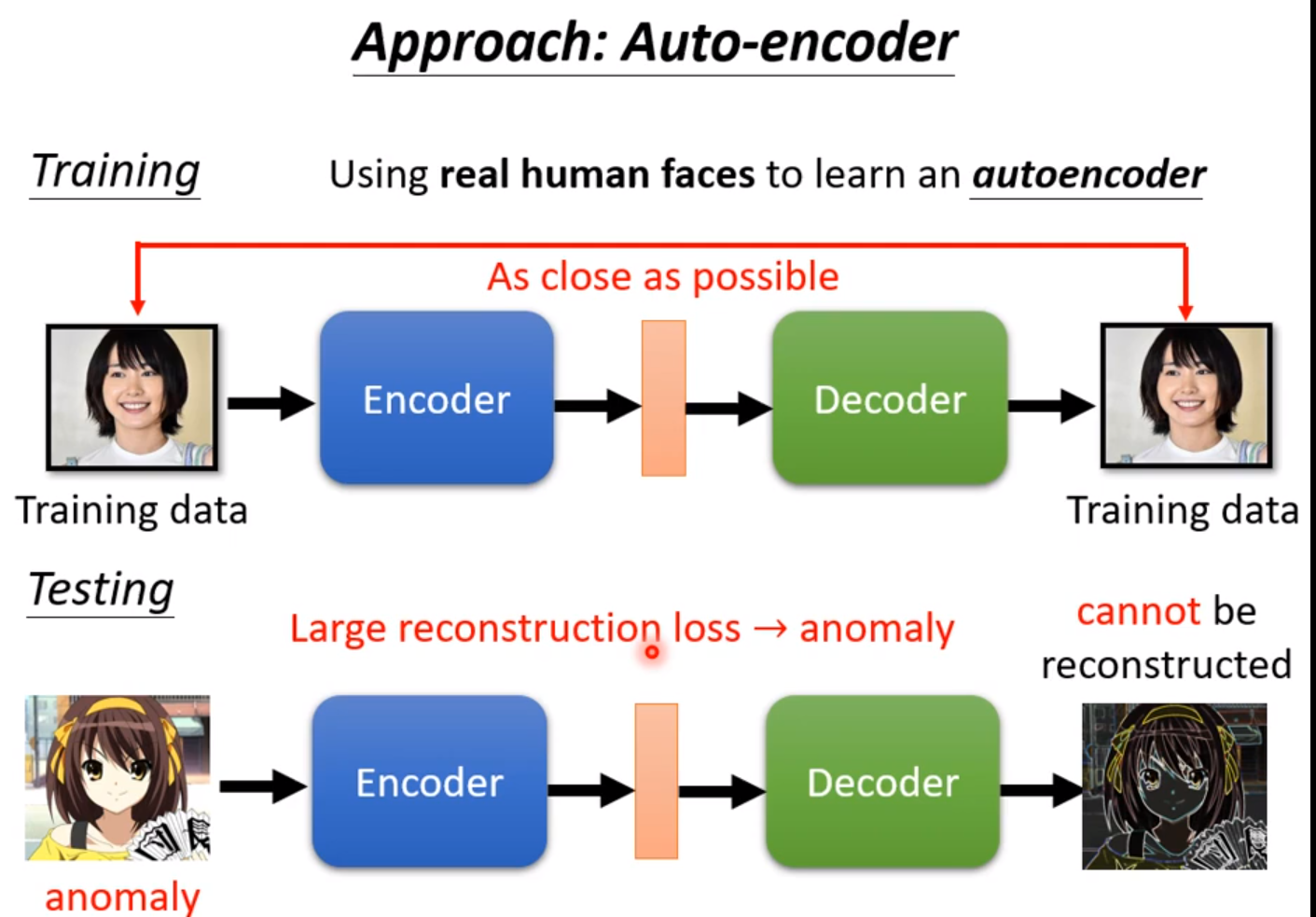
我们训练时让Decoder产生的输出越接近输入的图片越好,在检测时如果输出越解决输入则表明模型学习过类似的图片。如果相差很远,Reconstruction Loss很大,那么就是异常的图片。这个是异常检测的一个方法,实际上异常检测不一定用Auto-Encoder,还有很多技术。



