原始论文:arXiv:1406.2661v1
详细讲解请参考文章:http://www.gwylab.com/note-gans.html,这里文章讲解的内容不再重复赘述。

GAN可以用来构造各种数据,包括图片声音等等,应用:





GAN的理解
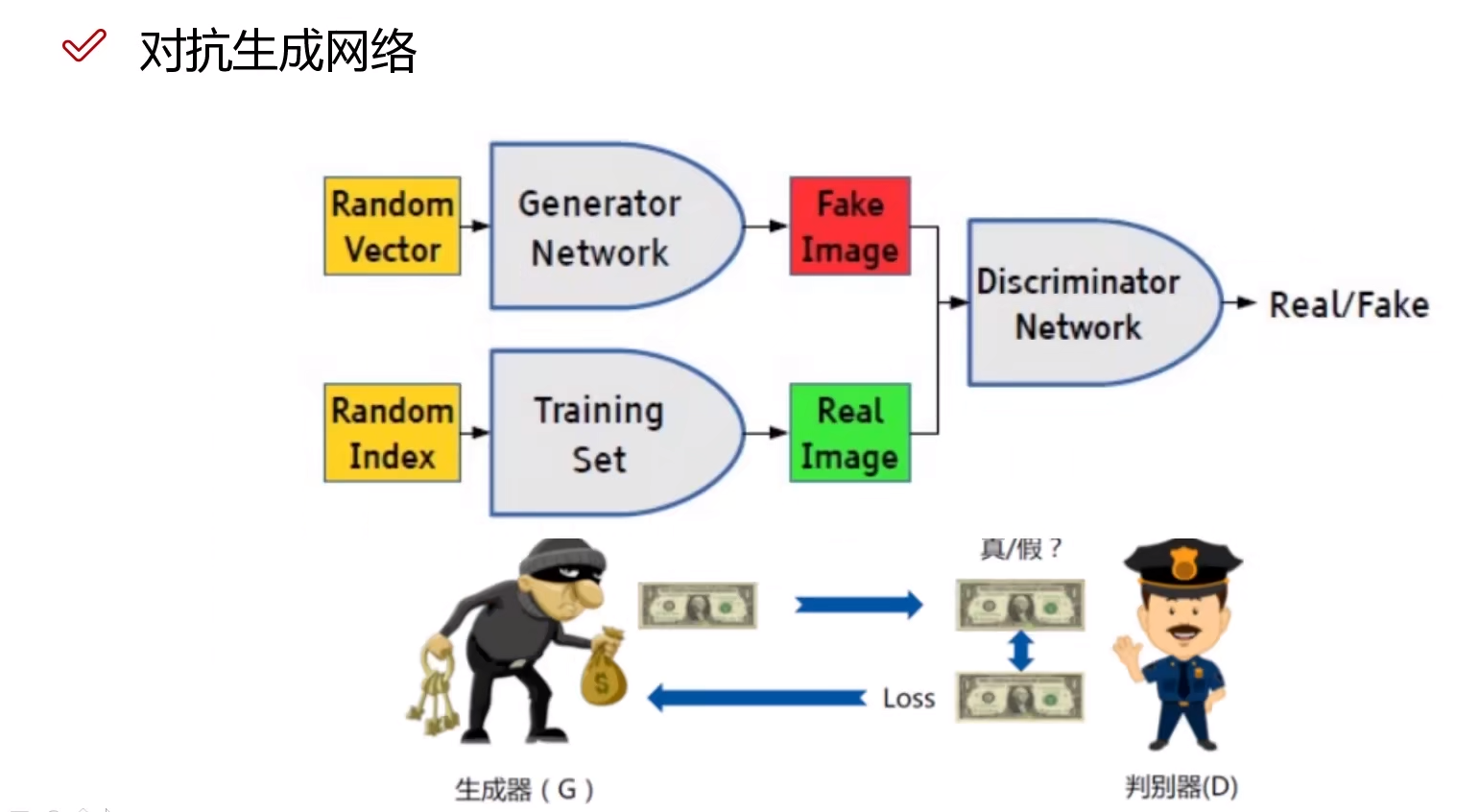
其中左边是一个生成器(Generator Network),负责生成假数据,它最终的目标是造出辨别器辨别不出来的假数据。右边是辨别器(Descriminator Network),负责辨别数据的真假,目标是把所有的假数据辨别出来。这就是对抗,在相互对抗的过程中,双方的辨别能力和造假能力都会不断升级,以达到更高的水准。
首先生成器输入的是一个随机的向量,通过一个神经网络,得到一个假数据,再输入判别网络,同时把真实数据输入判别网络,判别网络复制判断这两个数据的真假。
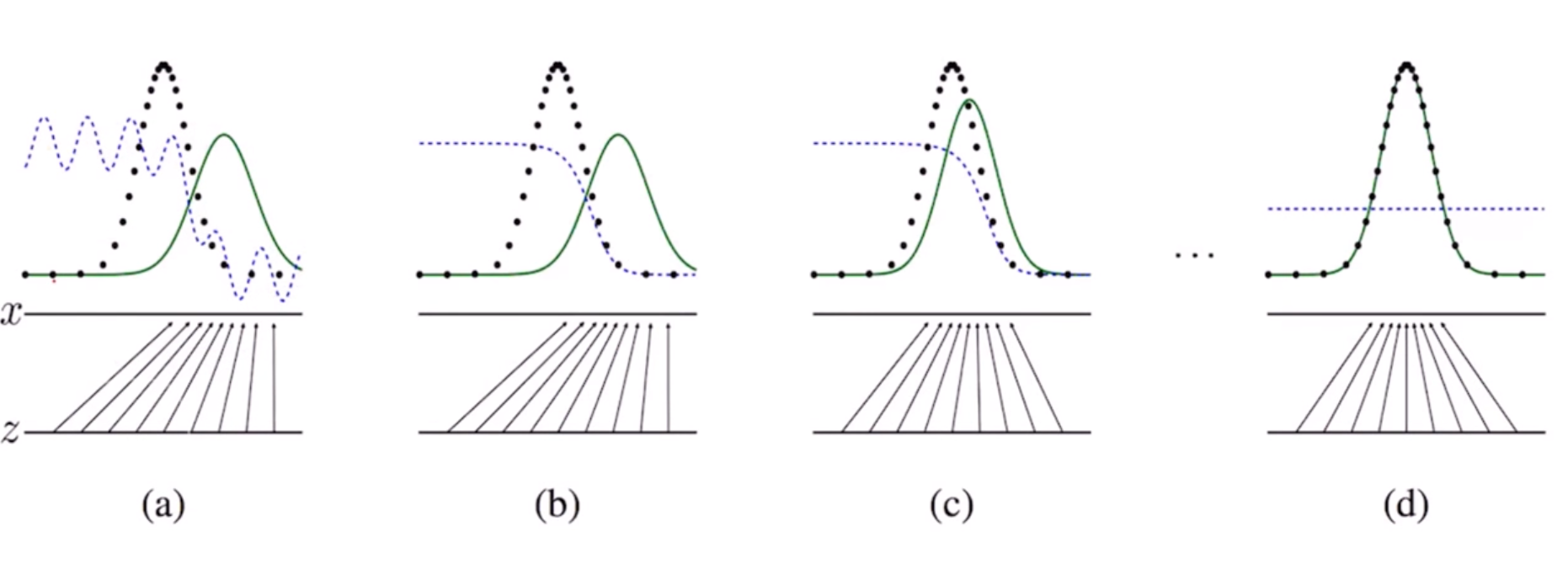
看上图,绿线是生成样本的概率分布,我们用随机噪声生成随机样本,黑色虚线是真实样本的概率分布,我们的目标是让生成样本的概率分布尽可能靠近真实样本的概率分布。中间的蓝色虚线是判决器,负责把两种样本分开。
GAN训练方案
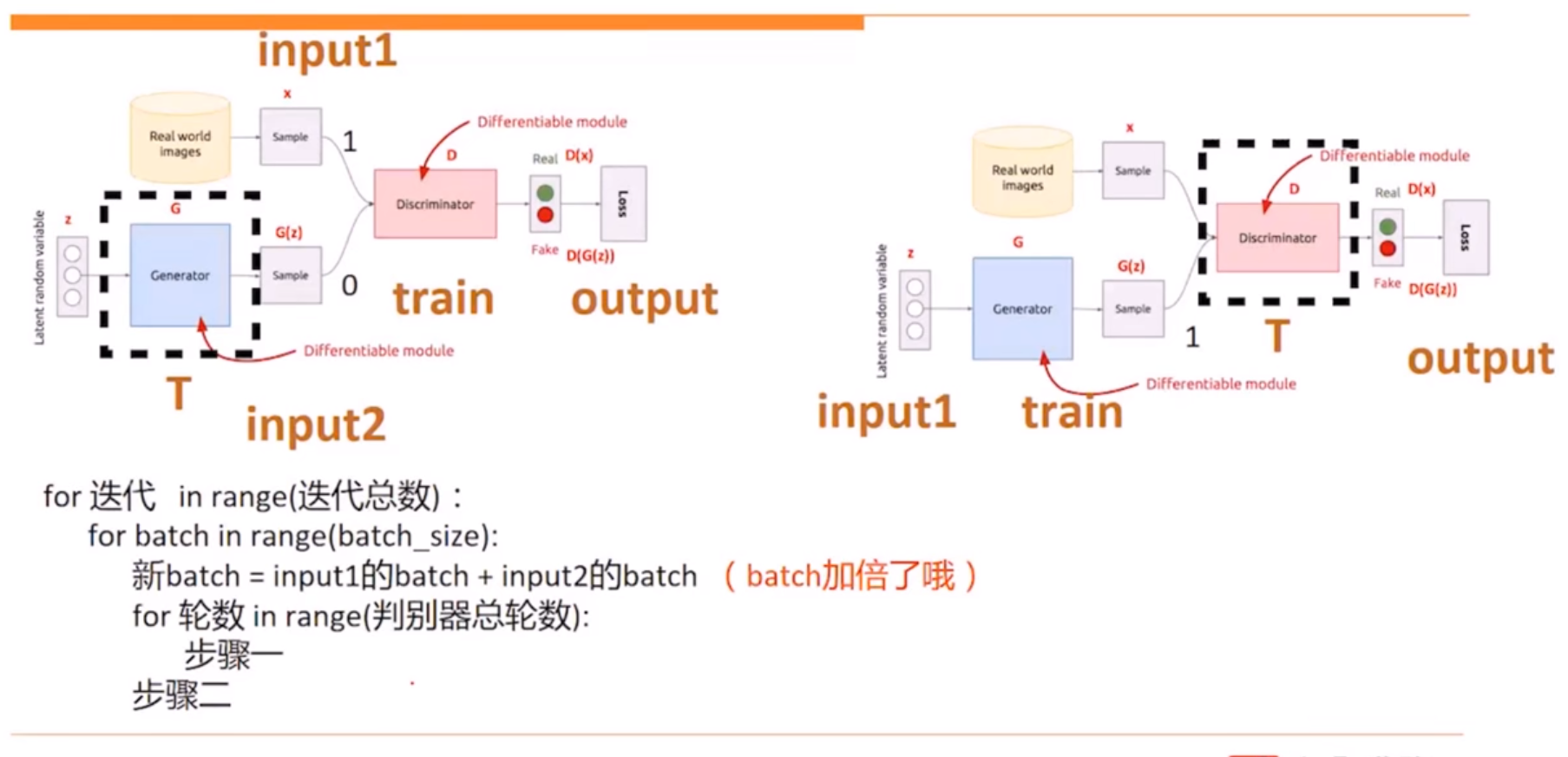
首先把生成器固定住,训练辨别器,让生成器生成样本和真实数据混在一起,然后给辨别器判决,通过梯度下降法来训练辨别器。第二步是辨别器训练后固定住,训练生成器,目标是让判决器出错。
先了解下纳什均衡,纳什均衡是指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。对应的,对于GAN,情况就是生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。这是双方网路都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。
GAN模型的目标函数如下:
$$
min_Gmax_D(D,G) = E_{x ~ p_{data}(x)}[logD(x)] + E_{z ~ p_{z}(x)}[log(1 - D(G(x)))]
$$
在这里,训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)和log(1—D(G(z)))),训练网络G最小化log(1-D(G(z))),即最大化D的损失。而训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
这就是GAN的最基础的流程,由此延伸出来的算法成百上千,百花齐放,各种各样的应用不一而足。
代码参考:https://blog.csdn.net/zandaoguang/article/details/102645230
GAN的诸多变种
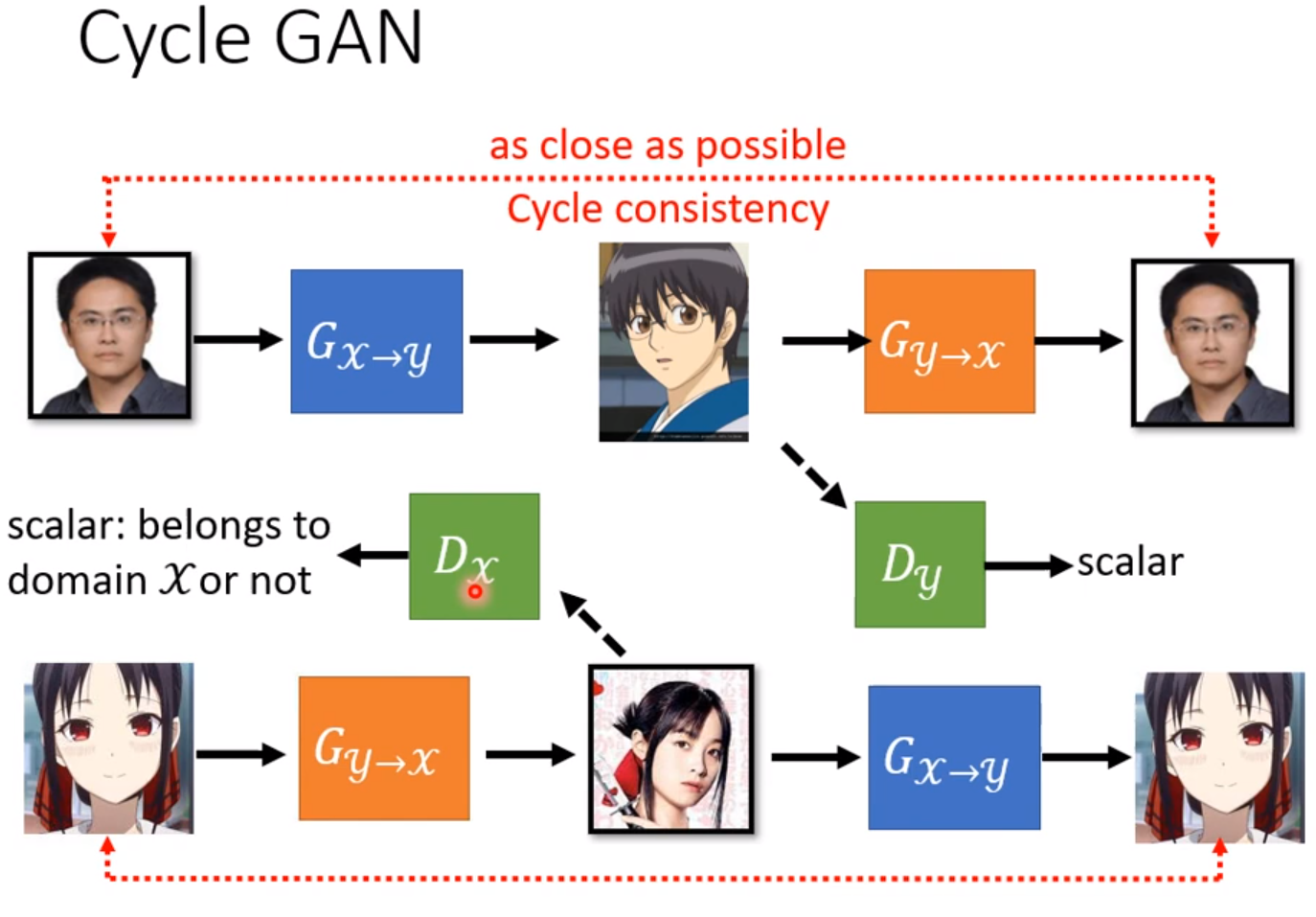
Cycle GAN